
NOTE: We have since launched the Numenta Platform for Intelligent Computing (NuPIC). Visit this blog for more details on our September 2023 release.
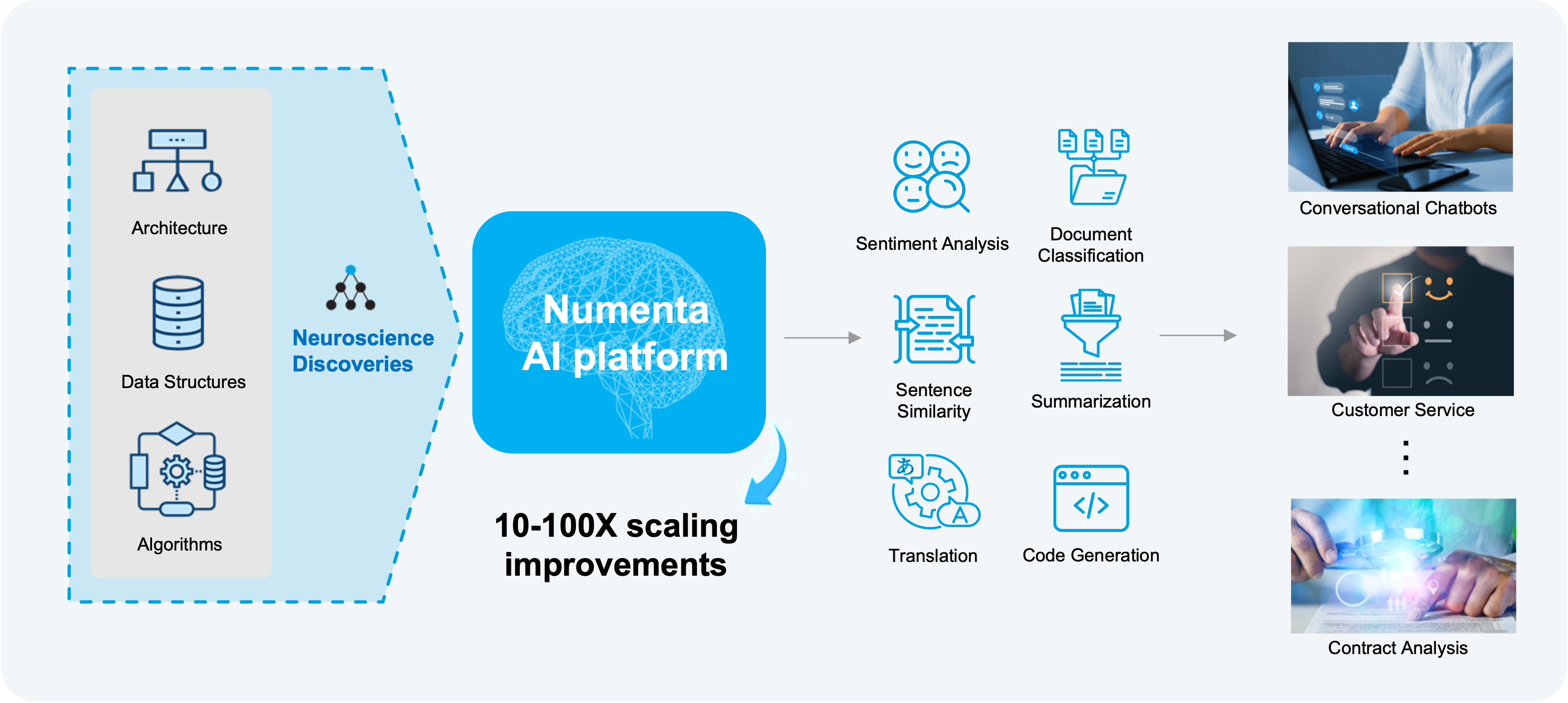
Built on a foundation of two decades of neuroscience research and breakthroughs in AI technology, we have developed a cutting-edge AI platform that uses neuroscience principles to process large amounts of language data quickly and accurately. It is optimized to run Large Language Models, such as Transformers, with high throughput, low latencies, and higher accuracies than traditional models.
Read on to learn how you can use our product to build sophisticated language-based applications with no machine learning experience required.
The rapidly changing landscape of LLMs
ChatGPT’s explosion onto the AI scene has put a spotlight on Transformers, and Large Language Models (LLMs) specifically. It has also sent nearly every boardroom scrambling to figure out how best to leverage the capabilities of LLMs. Yet despite their versatility and the consistent arrival of new models daily, LLMs can be incredibly expensive, painfully cumbersome, and nearly impossible to scale in production. They also bring heightened data privacy and security concerns as enterprises find it increasingly difficult to control their data when running these massive models. That’s where Numenta’s AI platform comes in. We’ve made it easy to run the models you need for a variety of tasks, at high speeds, on CPUs, and all on your own infrastructure.
What’s in the AI platform?
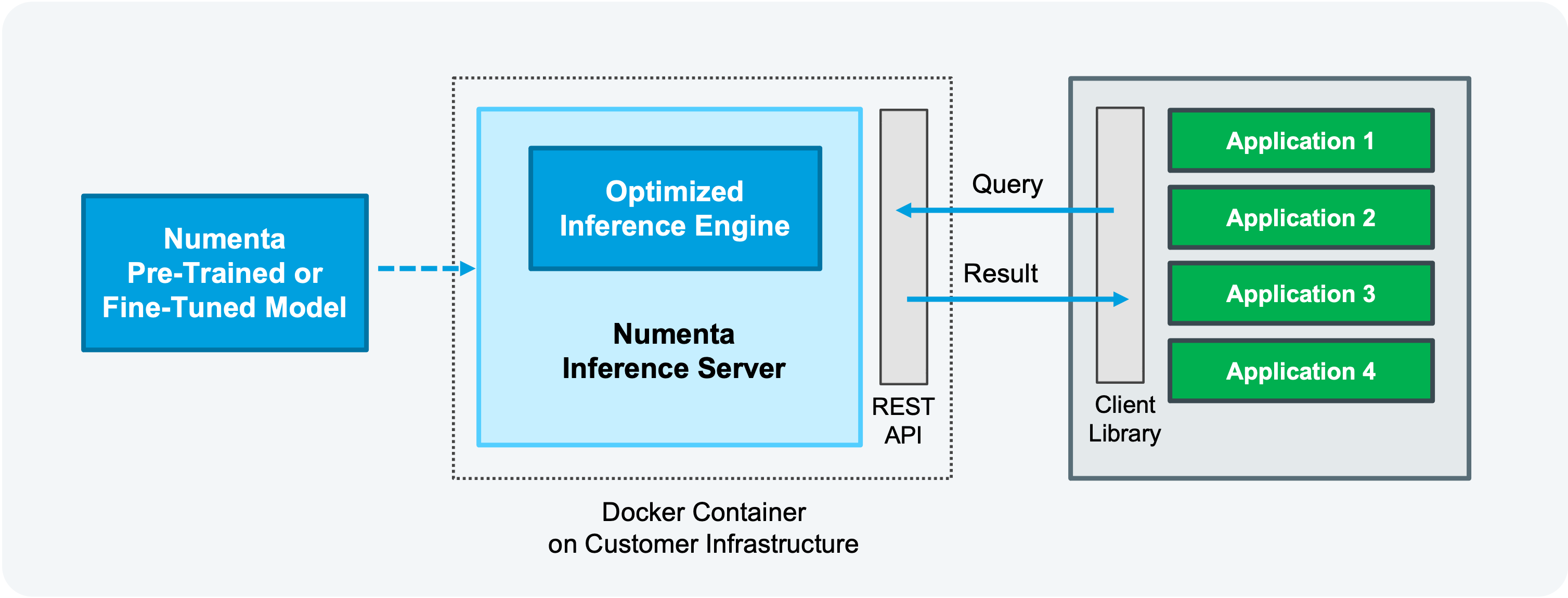
A core component of the platform is our inference server, which is optimized and designed to run LLMs with high throughput, low latencies, and higher accuracies than traditional models. With flexible model deployment tuning options, you can choose whether to optimize throughput or latency. Built using KServe HTTP/REST and GRPC inference protocols, you can seamlessly integrate the inference server into standard MLOps solutions.
The platform also comes with pre-trained models that any developer can use, with different speed and accuracy profiles, which lets you decide what matters most to your business. Today our models support sentiment analysis and sentence analysis using BERT-style models. For sentiment analysis, our platform can help you analyze your data to spot trends, improve customer satisfaction, tailor your offerings, and elevate your customer support. For sentence analysis, the platform helps you process massive data sets, categorize text, and uncover hidden connections.
Delivering 10-100x throughput and latency improvements
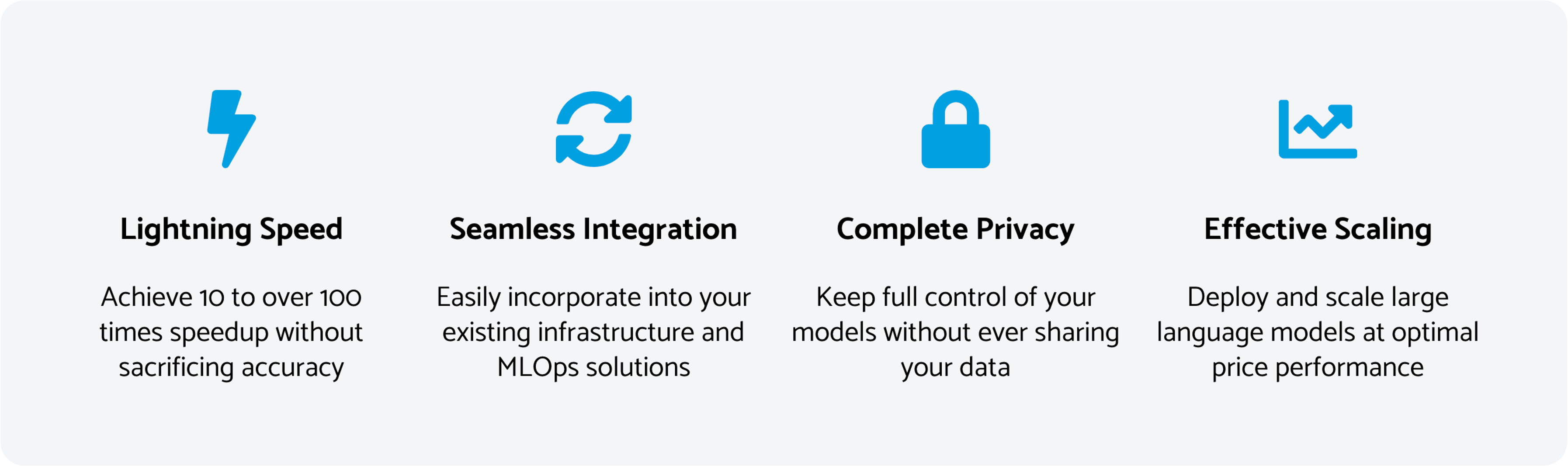
At the heart of the product is brain-based technology that provides unparalleled scaling of LLMs on CPUs. It can handle massive amounts of text and language data and deliver dramatic improvements in throughput, latency and price performance on today’s CPUs. This means you can get GPU-class performance from powerful LLMs at a fraction of the cost.
Our platform is also designed to facilitate easy integration and scalability. Whether it’s processing high-volume data streams or deploying GPT-scale language models, the platform can effortlessly adapt to varying workloads while maintaining top-tier performance – making it an optimal solution for businesses of all sizes.
Keep full control of your models and data
Moreover, in an era where data security is paramount, our AI platform stands out as a fully secure solution. Deployed on your infrastructure, your data never leaves your company’s physical or virtual boundaries. Running the platform on your infrastructure means:
- You can choose to run on any cloud provider or on-premise
- You retain full control of your models
- Your data remains private and never leaves your infrastructure
How is it deployed?
If you are familiar with Docker, then you already know how to deploy our platform. We deliver the product as a Docker container that’s deployed directly on your infrastructure. We’ve made it easy to launch instances on-premise or on your favorite cloud provider. You remain in full control of your models, and data never has to leave your internal network. Running the platform locally brings you better data security, lower latencies, reduced cost, and fewer compliance issues.
Who should use it?
We’ve designed our platform so that any developer or software engineer can quickly get up and running. No deep learning experience is required. If your business is building language-based applications and you need to process large amounts of language data quickly and cost-effectively, our AI platform can help.
Ready to get started? Want to learn more?
Let’s talk. We’re happy to set up a call where we’ll walk through a demo with you and explore how the platform can address your unique business needs and help you get started.
Once you’re ready to deploy, you can do so in 3 easy steps. Below is an example deployment for a sentence analysis use case.
Step 1: Launch the inference server
Using a python client, start the inference server with the following command. This will download our Docker image and start the Docker container:
./numenta_server.sh --start --expose –cpus 0-4
Step 2: Load model from model zoo
Next, select and load a pre-trained model from our model zoo. In this sentence analysis example, you might select “numenta-sentence-v1″:
self.model_name = "numenta-sentence-v1"
Step 3: Run model
After the model is loaded, you can start making requests to the server. The inputs are sentences that you want to compare for similarity.
sentences = [ “How old are you?”, “What is your age?”, “I have a green dog” ]
With just a few more lines of code, you can convert the text examples into numerical representations (i.e. embeddings). With the embeddings, you can then calculate similarity scores between each pair of sentences, which look something like the snippet below. The higher the similarity score, the more semantically similar the two sentences are, and vice versa.
# Results Similarity of sentence 0, 1: 503.73663330078125 Similarity of sentence 0, 2: 66.80323791503906
Step 4 (optional): Remove your deployment
You can stop the server and remove the Docker container at any time with the following command:
./numenta_server.sh –stop
What’s Coming
We have a robust roadmap that will incorporate additional components of our neuroscience research that leverage the brain’s structures and efficiencies. Additionally, we will continue to add optimized, pre-trained models to our library. We are also running an early access beta program where we’re working with a number of customers to explore new capabilities that are not yet available in the product. If you’re interested in getting early access to these advanced features, you can apply to our beta program here.
In the meantime, contact us to get started with the platform today and see how we can help you process large amounts of language data more efficiently and accurately. Follow us on LinkedIn and subscribe to our newsletter to stay up-to-date on all of our product news.