The Thousand Brains Project
About the Project
The efforts of Jeff Hawkins and Numenta to understand how the brain works started over 30 years ago and culminated in the last two years with the publication of the Thousand Brains Theory of Intelligence. Since then, we’ve been thinking about how to apply our insights about the neocortex to artificial intelligence. As described in this theory, it is clear that the brain works on principles fundamentally different from current AI systems. To build the kind of efficient and robust intelligence that we know humans are capable of, we need to design a new type of artificial intelligence. This is what the Thousand Brains Project is about.
In the past Numenta has been very open with their research, posting meeting recordings, making code open-source and building a large community around our algorithms. We are happy to announce that we are returning to this practice with the Thousand Brains Project. With funding from the Gates Foundation, among others, we are significantly expanding our internal research efforts and also calling for researchers around the world to follow, or even join this exciting project.
We have released a short technical document describing the core principles of the platform we are building. To be notified when the code and other resources are released, please sign up for the newsletter below. If you have a specific inquiry please send us an email to ThousandBrains@numenta.com.
Reverse Engineering the Neocortex
If we can understand how the neocortex implements intelligence, we can construct alternative AI systems that have the potential to revolutionize AI. Evolution has spent billions of years optimizing this efficient and incredibly adaptive system called the neocortex. Reverse-engineering it is no small feat, but if we can, it will serve as a blueprint for building artificial general intelligence.
We have made significant progress in understanding the neocortex, the basis of intelligence in mammals. Now we are taking the lessons from years of dedicated in-house research and the wealth of insights from neuroscience and using them to build a truly intelligent system. We believe that such a system will be the basis for applications that simply are not possible today.
A New, Open-Source, AI Framework
Our research team has been implementing a general AI framework that follows the principles of the Thousand Brains Theory. This framework will soon be available as an open-source code base. In addition, we will begin to actively publish our design and engineering progress. In order to further enable adoption, in the near future we will be pledging to not assert our patents related to the Thousand Brains Theory. You can find more details on our non-assert pledge and the patents included under this pledge here.
To encourage people to build on our ideas and apply our brain-based solutions and algorithms to their problems, we are putting together an easy-to-use SDK. We also want to encourage and foster an active research community and exchange around the Thousand Brains Theory and its application to AI.

Subscribe for Thousand Brains Project updates
Thousand Brains Principles
We have identified several core neocortical principles that are guiding our software architecture design. These principles are fundamentally different from those used by current AI systems. We believe that by adopting these principles, future AI systems will mitigate many of the problems that plague today’s AI such as the need for huge datasets, long training, high energy consumption, brittleness, inability to learn continuously, lack of explicit reasoning and ability to extrapolate, bias, and lack of interpretability. In addition, future AI systems built on the Thousand Brains principles will enable applications that cannot even be attempted with today’s AI.
Sensorimotor Learning
Learning in every intelligent species known is a fundamentally sensorimotor process. Neuroscience teaches us that every part of the neocortex is involved in processing movement signals and sends outputs to subcortical motor areas. We therefore believe that the future of AI lies in sensorimotor learning and models designed to deal with such settings.
Most AI systems today learn from huge, static, datasets, with major implications. First, this process is costly given the need to create and label these datasets. Second, these systems are unable to learn continuously from new information without retraining on the entire dataset. A system based on the Thousand Brains Theory will be able to ingest a continuous stream of (self-generated) sensory and motor information like a child experiences when playing with a new toy, exploring it with all her senses, and building a model of the object. The system actively interacts with the environment to obtain the information it needs to learn or to perform a certain task. Active learning makes the system efficient and allows it to quickly adapt to new inputs.
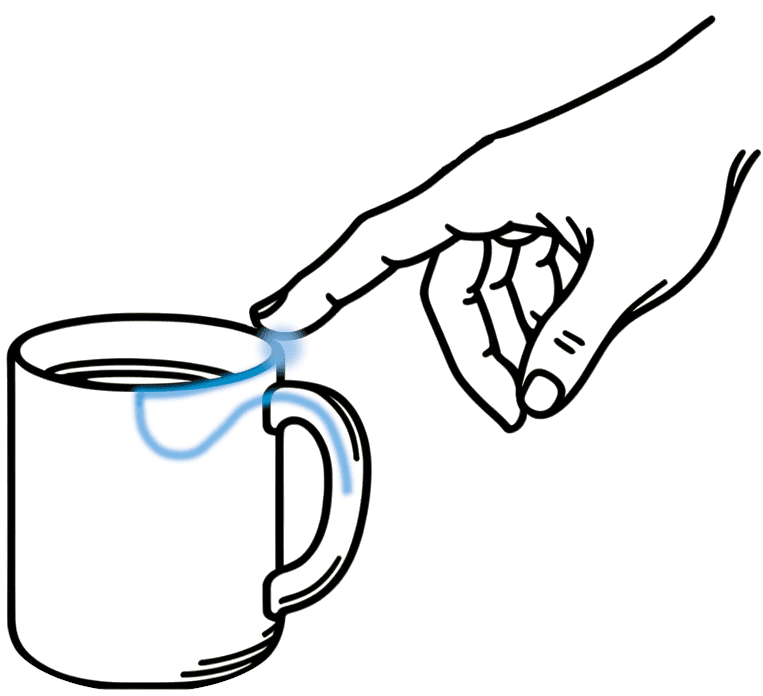
Reference Frames
The brain evolved efficient mechanisms, such as grid and place cells, to understand and store the constant stream of sensorimotor inputs. Representations that are learned by the brain are structured and make it possible to perform necessary tasks for survival quickly, such as path integration and planning.
While some existing AI systems are trained in sensorimotor settings (such as in reinforcement learning), the vast majority use the same modeling principles (like ANNs) as in supervised settings, bringing with it the same problems. In contrast, our models are specifically designed to learn from sensorimotor data and to build up structured representations. Those structured models allow for quick and sample-efficient learning and generalization. They also make the system more robust, give it the ability to reason, and enable easy interaction with environments and novel situations.
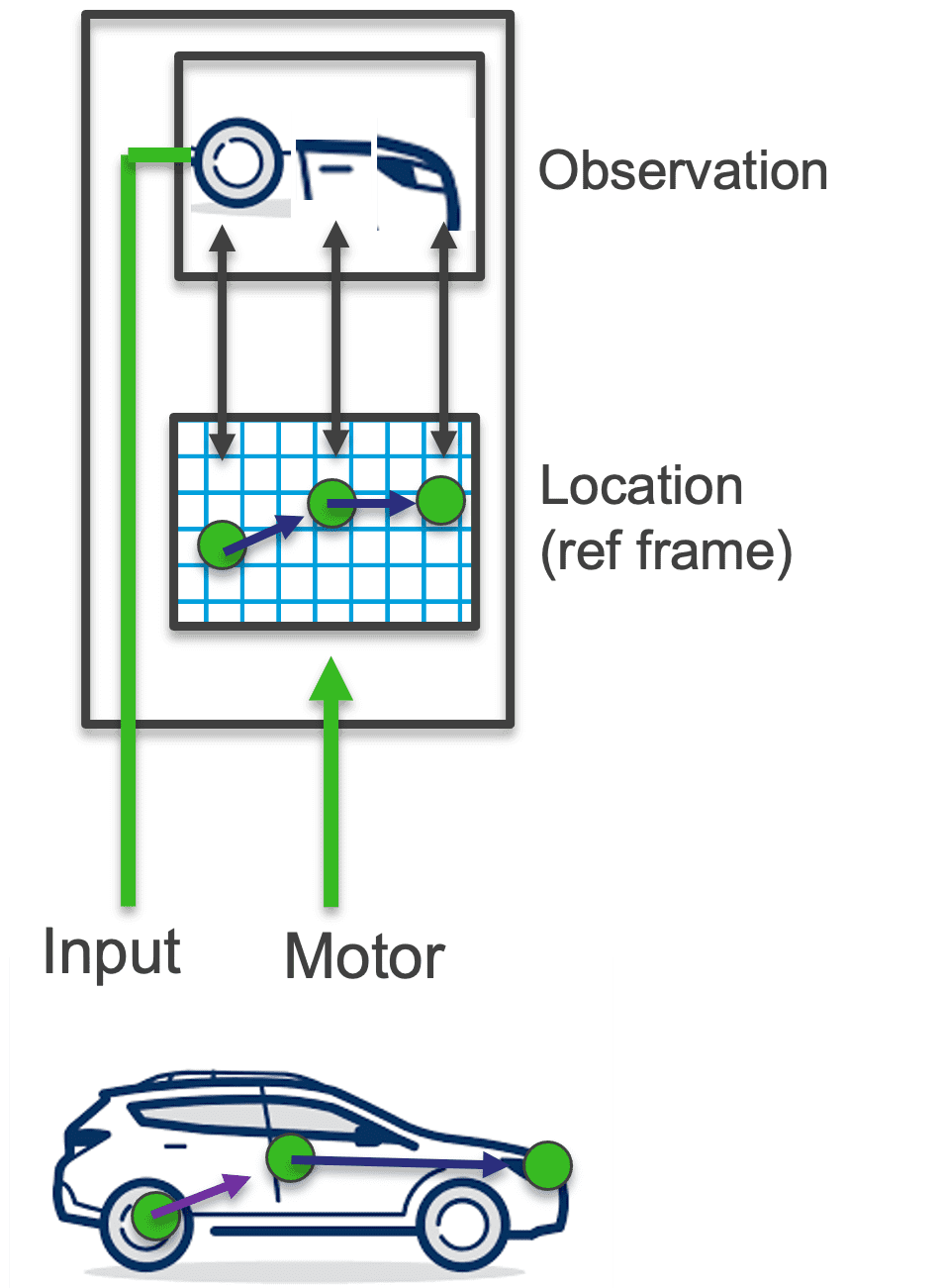
Modularity (A Thousand Brains)
The neocortex is made up of thousands of cortical columns. Each of these columns is a sensorimotor modeling system on its own with a complex and intricate structure. Neuroscientists talk about 6 different layers which are often divided into more sub-layers the closer you look. Over the past years we have studied the structure of cortical columns and the connections within and between them in detail.
In our implementation, we have cortical column-like units that can each learn complete objects from sensorimotor data. They communicate with each other using a common communication protocol. Inspired by long-range connections in the neocortex, they can communicate with each other laterally to reach a quick consensus and can also be arranged hierarchically to model compositional objects. The common communication protocol makes the system modular and allows for easy cross-modal communication and scalability.
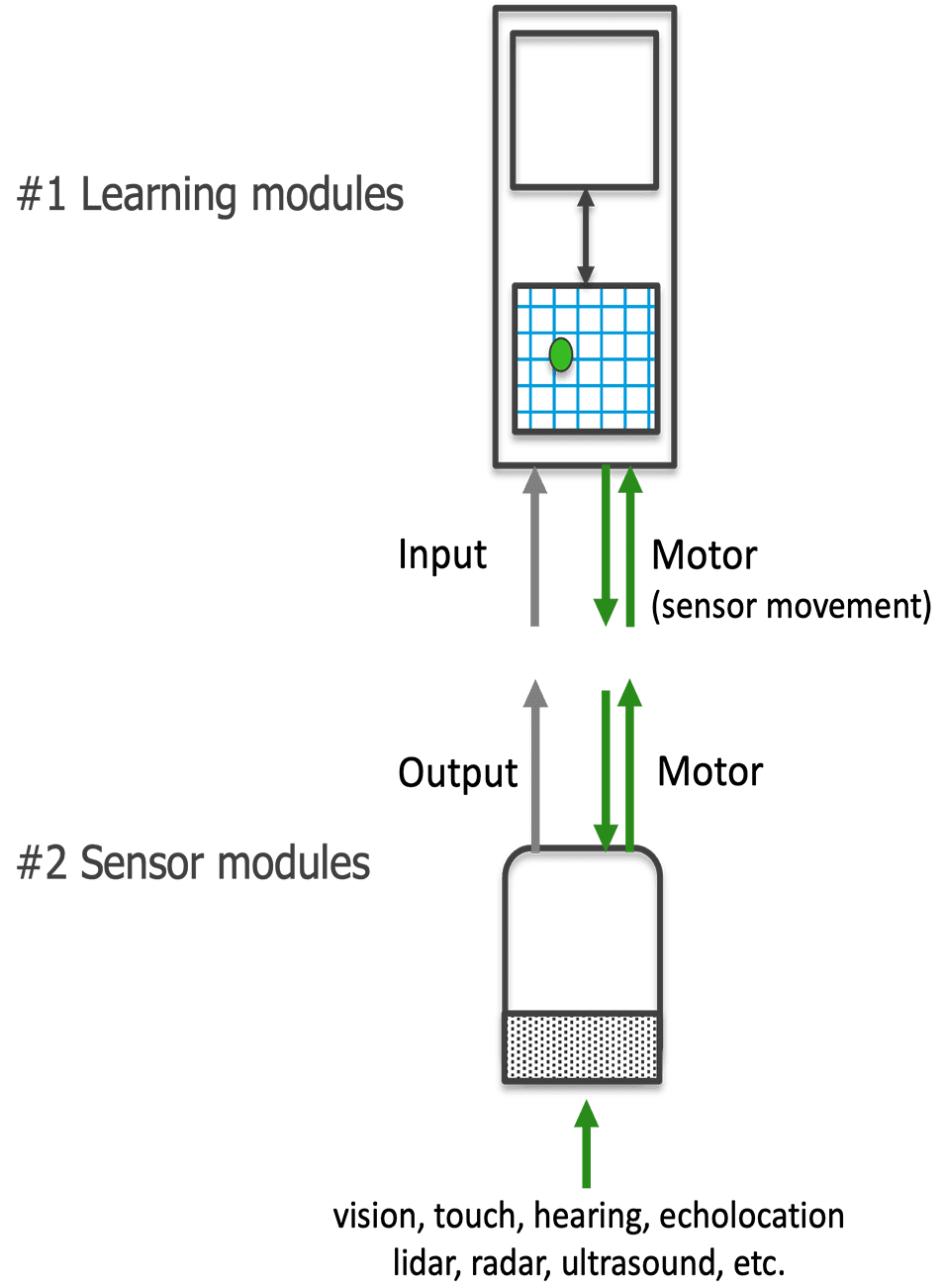
The SDK
In our SDK we will provide a general framework for learning with two different modules: Learning modules (LM) and sensor modules (SM). Learning modules are like cortical columns and learn structured models of the world from sensorimotor data. Sensor modules are the interface between the environment and the system and convert input from a specific modality into the common communication protocol.
An LM does not care from which modality it receives input and multiple LMs receiving input from different modalities can communicate effortlessly. Practitioners can implement custom SMs for their specific sensors and plug them into the system. A system can also use different types of LMs, as long as they all adhere to the common communication protocol. This makes the system extremely general and flexible.
More Information
We are in the process of preparing all our progress from the past years in a digestible format and will release it over the coming months. If you would like to be notified about updates, please email us, follow us on X, or subscribe to our Youtube channel. In the meantime we have compiled a document detailing the core principles and goals of the project.
Join our team
Frequently Asked Questions
We aim to build a general-purpose system that is not optimized for one specific application. Think of it as similar to Artificial Neural Networks (ANNs), which can be applied to all kinds of different problems and are a general tool for modeling data. Our system will be aimed at modeling sensorimotor data, not static datasets. This means the input to the system should contain sensor and motor information. The system then models this data and can output motor commands.
The most natural application is robotics, with physical sensors and actuators. However, the system should also be able to generalize to more abstract sensorimotor setups, such as navigating the web or conceptual space. As another example, reading and producing language can be framed as a sensorimotor task where the sensor moves through the sentence space, and action outputs could produce the letters of the alphabet in a meaningful sequence. Due to the communication protocol between the sensor and learning module, the system can effortlessly integrate multiple modalities and even ground language in physical models learned through other senses like vision or touch.
Much of today’s AI is based on learning from giant datasets by training ANNs on vast clusters of GPUs. This not only burns a lot of energy and requires a large dataset, but it is also fundamentally different from how humans learn. We know that there is a more efficient way of learning; we do it every day with our brain, which uses about as much energy as a light bulb. So why not use what we know about the brain to make AI more efficient and robust?
This project is an ambitious endeavor to rethink AI from the ground up. We know there is a lot of hype around LLMs, and we believe that they will remain useful tools in the future, but they are not as efficient as the neocortex. In the Thousand Brains Project, we want to build an open-source platform that will catalyze a new type of AI. This AI learns continuously and efficiently through active interaction with the world, just like children do.
We aim to make our conceptual progress available quickly by publishing recordings of all our research meetings on YouTube. Any engineering progress will automatically be available as part of our open-source code base. We keep track of our system’s capabilities by frequently running a suite of benchmark experiments and evaluating the effectiveness of any new features we introduce. The results of these will also be visible in our GitHub repository.
In addition to making all incremental progress visible, we will publish more succinct write-ups of our progress and results at academic conferences and in peer-reviewed journals. We also plan to produce more condensed informational content through a podcast and YouTube videos.
No, LLMs are incredibly useful and powerful for various applications. In fact, Numenta has a product called NuPIC, which stands for Numenta Platform for Intelligent Computing, that’s designed to make LLMs faster and more efficient.
However, we believe that the current approach most researchers and companies employ of incrementally adding small features to ANNs/LLMs will lead to diminishing returns over the next few years. Developing genuine human-like intelligence demands a bold, innovative departure from the norm. As we rethink AI from the ground up, we anticipate a longer period of initial investment with little return that will eventually compound to unlock potential that is unreachable with today’s solutions. We believe that this more human-like artificial intelligence will be what people think of when asked about AI in the future. At the same time, we see LLMs as a tool that will continue to be useful for specific problems, much like the calculator is today.
The system we are building in the Thousand Brains Project has many advantages over current popular approaches. For one, it is much more energy and data-efficient. It can learn faster and from less data than deep learning approaches. This means that it can learn from higher-quality data and be deployed in applications where data is scarce. It can also continually add new knowledge to its models without forgetting old knowledge. The system is always learning, actively testing hypotheses, and improving its current models of whatever environment it is learning in.
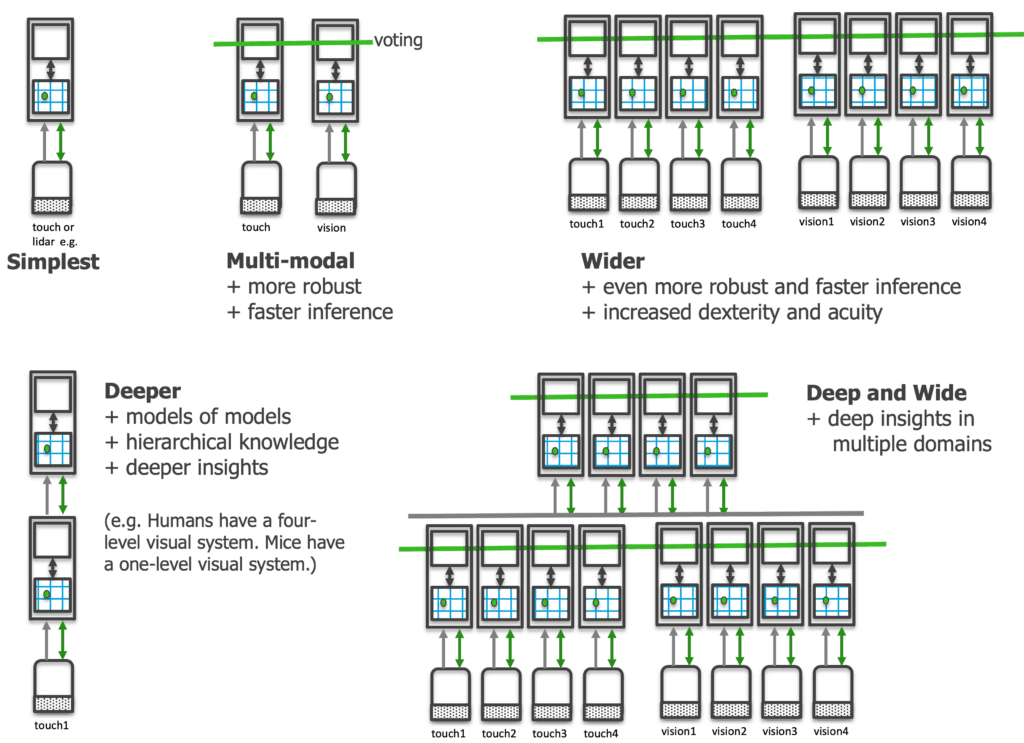
Another advantage is the system’s scalability and modularity. Due to the modular and general structure of the learning and sensor modules, one can build extremely flexible architectures tailored to an application’s specific needs. A small application may only require a single learning module to model it, while a large and complex application could use thousands of learning modules and even stack them hierarchically. The common communication protocol makes multimodal integration effortless.
Using reference frames for modeling allows for easier generalization, more robust representations, and more interpretability. To sum it up, the system is good at all the things that humans are good at, but current AI is not.
The TBP and HTM are both based on years of neuroscience research at Numenta and other labs across the world. They both implement principles we learned from the neocortex in code to build intelligent machines. However, they are entirely separate implementations and differ in which principles they focus on. While HTM focuses more on the lower-level computational principles such as sparse distributed representations (SDR), biologically plausible learning rules, and sequence memory, the TBP focuses more on the higher-level principles such as sensorimotor learning, the cortical column as a general and repeatable modeling unit, and models structured by reference frames.
In the TBP, we are building a general framework based on the principles of the thousand brains theory. We have sensor modules that convert raw sensor data into a common communication protocol and learning modules, which are general, sensorimotor modeling units that can get input from any sensor module or learning module. Importantly, all communication within the system involves movement information, and models learned within the LMs incorporate this motion information into their reference frames.
There can be many types of learning modules as long as they adhere to the communication protocol and can model sensorimotor data. This means there could be a learning module that uses HTM (with some mechanism to handle the movement data, such as grid cells). However, the learning modules do not need to use HTM, and we usually don’t use HTM-based modules in our current implementation.
We are dedicated to making the code open source as soon as possible. Currently, we are hiring a team and putting documentation in place so that once the code is released, people can get started easily and get support when needed. We are hoping to make the code open source by the end of 2024, earlier if possible. Sign up for updates below.
We are excited about anyone interested in this project, and we want to build an active open-source community around it. There are different ways you can get involved. If you are an engineer or researcher with ideas on improving our implementation, we would be delighted to have you contribute to our code base. Please sign up for updates on when the code will be available.
Second, if you have a specific sensorimotor task you are trying to solve, we would love for you to try our approach. We will work on making an easy-to-use SDK so you can just plug in your sensors and actuators, and our system does the modeling for you. We will start hosting regular research and industry workshops and would be happy to have you join.
We are also planning to host a series of invited speakers again, so please let us know if you have research that you would like to present and discuss with us. Lastly, if you want to join our Numenta team, please apply for one of our open positions.
The Thousand Brains project is partially funded by the Gates Foundation. We are providing the Gates Foundation with regular updates on our progress, and they are facilitating exchanges with related research groups and potential applications, especially in global health. We hope that our technology will have a big impact on AI and global health applications and will make them more available in low-income countries.
Over the following months, we will release much more information, such as meeting recordings from the past years, new talks and meetups, documentation, and code. If you have any specific questions, feel free to reach out to us at thousandbrains@numenta.com.