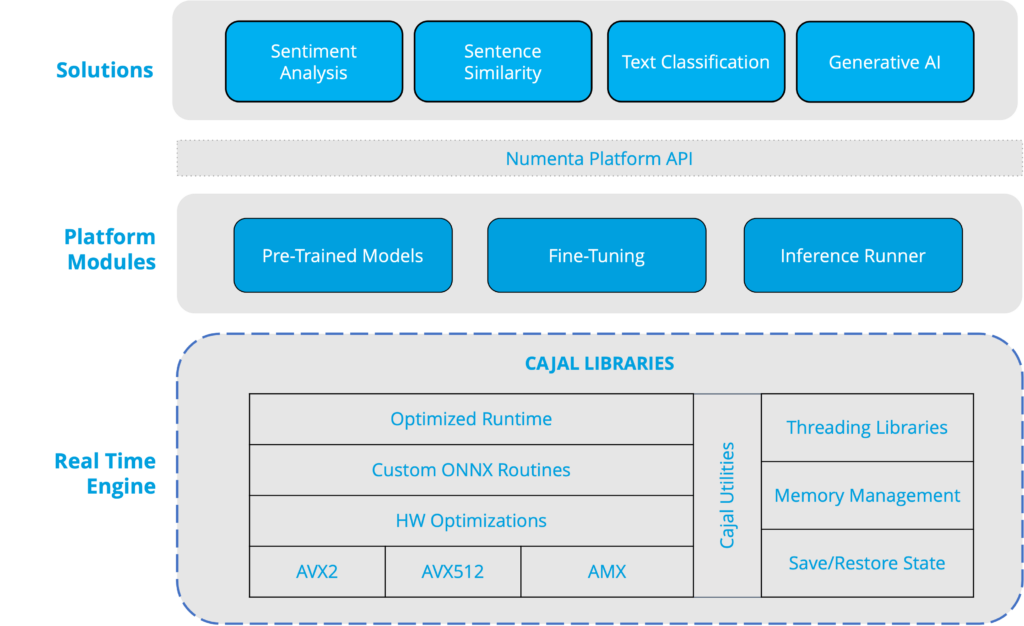
Within the NuPIC Inference Server is the NuPIC real-time engine, built using our internal Cajal libraries (named after the very first neuroscientist Santiago Ramón y Cajal). The Cajal libraries are written using a combination of C++ and assembler. They include an optimized runtime, custom ONNX routines, and a set of hardware optimizations that leverage SIMD instructions, specifically AVX2, AVX512, and AMX.
The design of Cajal enables NuPIC to realize unparalleled throughput. Cajal attempts to minimize data movement and memory bandwidth. Memory management routines maximize the use of L1 and L2 cache and share memory between models as appropriate. Internally, our AMX codebase uses the bf16 format which optimizes the bandwidth required for matrix calculations without compromising accuracy, a common problem with more aggressive quantization and lower precision formats. No specific quantization step is required to use models within NuPIC.