HTM Studio
Find Real-Time Anomalies in your Streaming Data
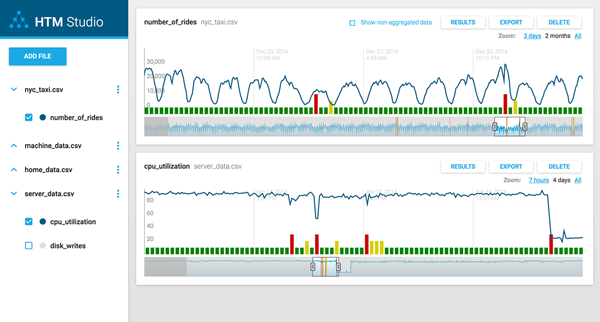
HTM Studio allows you to test whether our Hierarchical Temporal Memory (HTM) algorithms will find anomalies in your data. With just one click, you can uncover anomalies other techniques cannot find in your numeric, time-series data, in minutes.
Play Video
Video: HTM Studio Introduction (01:37)
Features
No Coding Requires
Skip the hassle of setting parameters. Discover anomalies with one click.
Run Simultaneous Models
Run multiple data streams simultaneously and compare discovered anomalies.
Pre-Loaded Datasets
Don’t have your own data readily available? Experiment with our pre-loaded datasets, and see how HTM can be applied to a variety of use cases.
Data Privacy
Add local CSV (comma-separated value) files quickly with no upload or privacy issues.
Summarized Results
Visualize and export your results.
Use Cases

Preventative Maintenance
Monitor machine sensors to detect failures before they occur.

IoT Sensors
Understand energy usage and adjust resources in a connected building.

Traffic Patterns
Identify unusual patterns in direction or speed from a vehicle.

Network Servers
Identify network changes and potential server degradation.
Get Started
To get the full HTM Studio experience, watch our short walk-through video.
Data imported into HTM Studio must be formatted to meet certain conditions. See requirements and watch our brief instructional videos to learn how to prepare your data.

Play Video
Video: HTM Studio Walk-through (04:41)
Date/Time Format
Data imported into HTM Studio must be in CSV file format and meet the following conditions:
- Only one Date/Time column
- Only one header row
- Number of rows in the CSV file should be minimum of 400.
- Values in numeric columns will be skipped if equal to:
“NaN”, “None”, “null”, “N/A”, “NA” (not case sensitive) - Any number of numeric columns
- Data is listed in chronological order
- Date/Time column must be in a supported format
- Unix timestamp support (both milliseconds and seconds) as long as the column name contains the words “time” or “date” (case insensitive)

Play Video
Video: Date/Time Format Tutorial (04:28)
Isolating Data Sources
CSV files must contain data that has only been generated from one source. If you have multiple sources, you will need to split your data by source and into separate CSV files.

Play Video
Video: Isolating Data Sources Tutorial (02:47)
Frequently Asked Questions
Contact Us to discuss adding HTM technology to your system and for licensing opportunities. You can also engage with our HTM open source community. There you can ask HTM related questions and find learning resources to develop a project using HTM.
Yes, the source is available on our GitHub repository .
We support Mac OS/X (versions Yosemite and El Capitan) and Windows (64-bit versions 7, 8 and 10).
You can create a mock column for date / time by numbering each row (for example: 0, 1, 2, 3) in your file and ensure you have a header row, with the mock column named “time”.
HTM Studio only accepts CSV files that meet certain requirements, which can be found in the get started section.
Aggregation refers to the process of combining multiple values over a given period of time. This can be very useful if you are collecting data at a high frequency or if you have noisy data. Aggregating can reduce the amount of noise and help the HTM model learn faster. HTM Studio determines whether and how much to aggregate the input records before feeding them into the HTM model.
The ideal aggregation window is one that allows you to aggregate as much as you can but not too much. There is no one-size-fits-all value, as aggregation is application-dependent. HTM Studio makes a good first guess with any data set, but getting the best aggregation possible requires knowledge about the application itself. HTM Studio defaults to an automated technique that determines a best-effort aggregation window for your data. However, you can change the value of the aggregation window (or choose to not aggregate the data at all) in “advanced settings” when you create a new model. For more information on how to change the aggregation window, click here.
When you aggregate your data, you are changing the number of data points that HTM sees. In some cases, aggregating your data may cause you to miss anomalies and in other cases, it may help you find anomalies by tuning out noise. The goal is to aggregate your data as much as possible but not too much. You can experiment with different aggregation windows in HTM Studio to see how it changes your results. To see an example, click here.
HTM Studio determines the optimal parameters for each Hierarchical Temporal Memory (HTM) model and in some cases, aggregates your data for analysis. You can see what these parameters are in the advanced settings. We recommend that you follow the determined parameters for the best possible analysis. However, you may modify these parameters by clicking the advanced settings. For example, you can change the aggregation method and period. Or you can also suppress data aggregation by disabling the check box. See question “What does aggregate my data mean?” for information on aggregating data.
HTM Studio begins to build models from the metric in your data immediately. During the initial learning period, the anomaly results are displayed as grey bars with the value “N/A” displayed in the chart area. Once a HTM model has enough data points to learn on, it will display anomalies indicated by green, yellow and red bars.
HTM Studio first learns patterns in your data and builds a model to predict what is likely to happen in the next CSV record. Based on these predictions, the HTM algorithm generates an anomaly score for each data point. If you would like to learn more about anomaly detection, please refer to our Science of Anomaly Detection White Paper .
There are many reasons why this may occur, but some of the most common are:
- If your data does not include any abnormal patterns, then HTM Studio cannot detect any anomalies.
- HTM Studio learns and builds models from your data during its initial learning period, see question “What is the initial learning period?” HTM Studio needs to have enough data points, at least 500, to learn patterns and detect anomalies. See a full list of requirements here.
- HTM Studio has not detected any anomalies during a given time period for this data. Although some of the data may look unusual, if HTM Studio has previously learned a pattern then it will not find it anomalous. Try looking at older data in the chart to see if similar patterns have previously occurred.
Feedback
Provide your feedback on HTM Studio via the form below, or email htm-studio@numenta.com for further information on HTM.
Fill out my online form.
Resources
- HTM Studio Data Sheet
Download this one-page data sheet to learn more about HTM Studio. - Science of Anomaly Detection Video
Learn about the science behind our HTM machine intelligence algorithms in this educational video. - Numenta Anomaly Benchmark (NAB)
An open-source benchmark for evaluating anomaly detection in streaming data.