
20x inference acceleration for long sequence length tasks on Intel Xeon Max Series CPUs
Numenta technologies running on the Intel 4th Gen Xeon Max Series CPU enables unparalleled performance speedups for longer sequence length tasks.
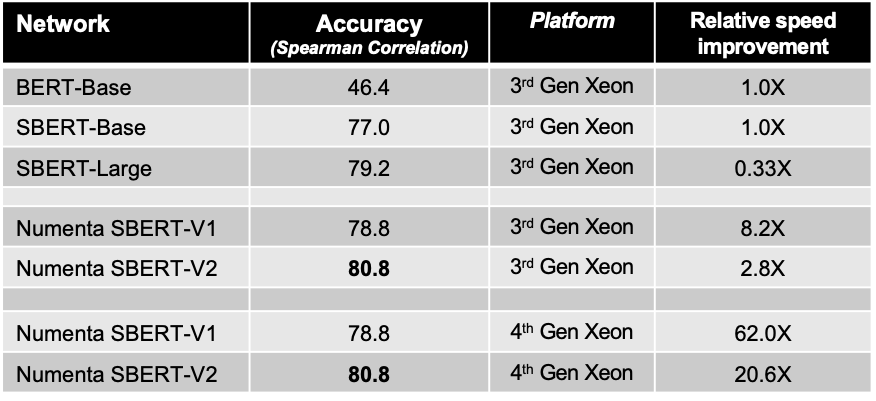
This table shows results for standard and Numenta optimized models on the Semantic Sentence Similarity Benchmark (STSB), a popular NLP tool that measures how effectively models capture nuanced, semantic similarities between sentence pairs.
The first few rows in the table are standard models. Given that BERT is designed to look at the context of words in a sentence while SBERT measures how similar two sentences are, SBERT models have much better accuracy on this benchmark. In this case, SBERT-Base gets a score of 77.0, which is dramatically higher than the BERT-Base score of 46.4. Since their model architecture is the same, there is no speed improvement. The SBERT-Large model is 3 times as big, which gives it an even higher accuracy score of 79.2, but makes it 3 times slower than the Base models.
Now if we look at the Numenta models running on Intel’s 3rd Gen Xeon, we see that the first model offers higher accuracy than SBERT-Base and an 8x speedup. The second Numenta model offers even higher accuracy than SBERT-Large, but in this case, rather than running 3 times slower than BERT-Base, it runs 3 times faster. When our models run on Intel’s 4th Gen Xeon, the speed-ups are even more dramatic, at 20-60x faster.
* The above BERT-Base and SBERT-Base accuracy baselines were sourced from the paper “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks” by Reimers and Gurevych. To facilitate comparison, our BERT models were pre-trained on the same dataset. Higher accuracies on STSB can be obtained by using different model architectures and more extensive pre-training regimes.
Numenta technologies running on the Intel 4th Gen Xeon Max Series CPU enables unparalleled performance speedups for longer sequence length tasks.

Numenta technologies combined with the new Advanced Matrix Extensions (Intel AMX) in the 4th Gen Intel Xeon Scalable processors yield breakthrough results.
Numenta Transformer models significantly accelerate CPU inference while maintaining competitive accuracy.