Accelerating deep learning models while reducing costs
Transformers have become the deep learning model of choice for many NLP applications, but despite the high accuracy they deliver, their size and complexity make them costly to deploy. New solutions are needed to combat exponential model growth and the associated costs that typically come with performance acceleration.
SOLUTION
Highly performant, brain-based models
By applying insights from the structure and function of cortical circuitry observed in the brain, we’ve developed deep learning performance techniques and highly optimized transformer models. Our models significantly accelerate CPU inference while maintaining competitive accuracy.
RESULTS
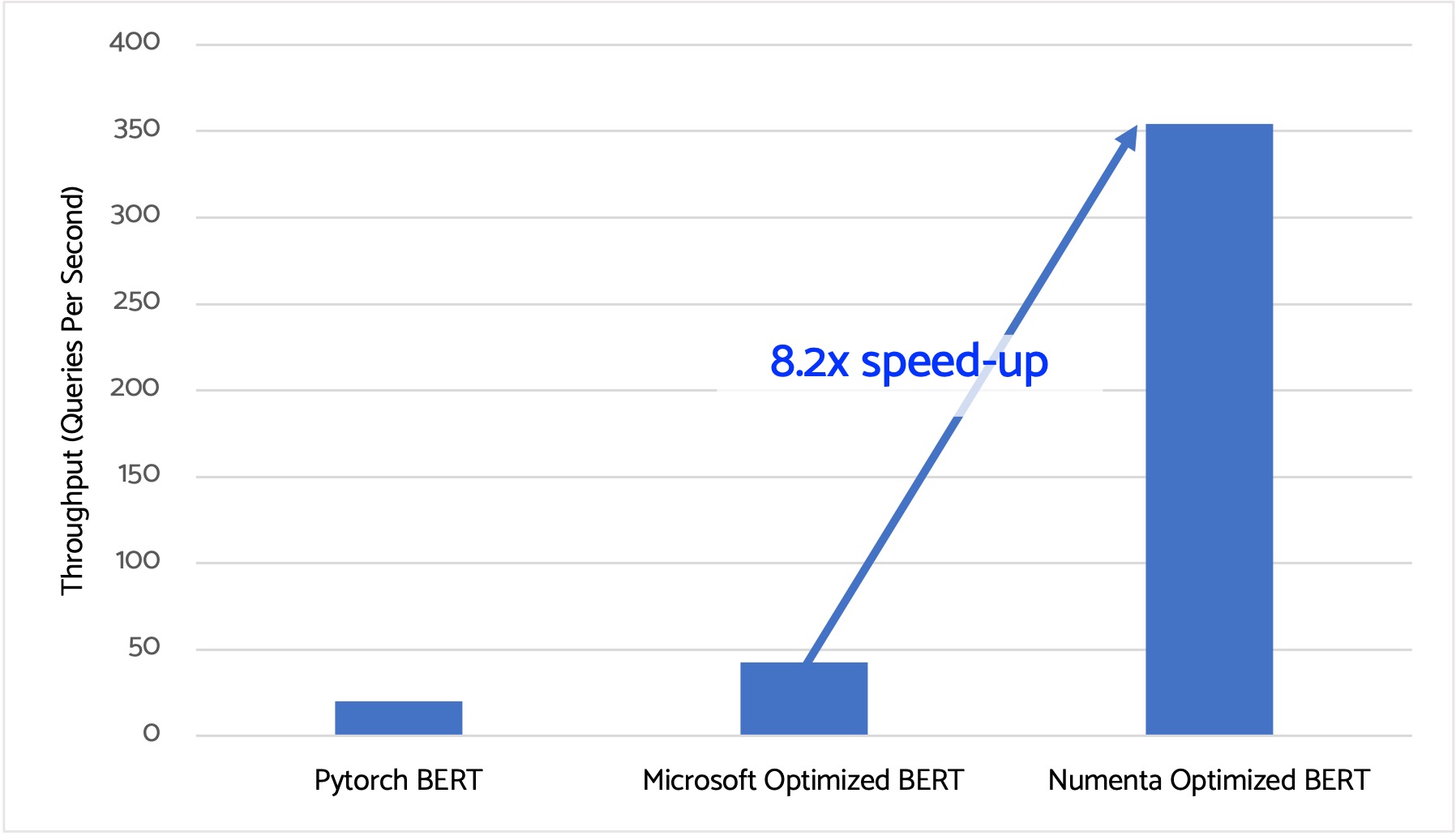
8x performance improvement over the industry standard
Two key metrics for many AI and NLP applications are throughput and latency. Throughput measures how many transactions occur within a given amount of time; latency measures how much time each transaction takes. Different applications may prioritize one over the other, and there is often a trade-off between high-throughput and low latency.
In this case, we optimized for high throughput. To measure the inference throughput acceleration of our models, we used the popular transformer-based language model BERT-Base. We compared our optimized model against a standard BERT-Base running on Microsoft’s hand-optimized ONNX runner. As the chart below demonstrates, we observed more than 8x higher throughput using our optimized model.
Models are running BERT-Base on an Intel Xeon server (AWS m6i.2xlarge), with Sequence Length 64, Batch Size 1, using 1 Socket and 4 Cores
BENEFITS
Dramatic inference performance improvements open new possibilities
This throughput speed-up provides several benefits, enabling:
Ability to run larger models at lower cost
Ability to run more models on existing infrastructure
Ability to scale to more customers
New applications that require deep learning models
Easier deployment of deep learning models in new domains
With our neuroscience-based optimization techniques, we shift the model accuracy scaling laws such that at a fixed cost, or a given performance level, our models achieve higher accuracies than their standard counterparts.
Numenta technologies combined with the new Advanced Matrix Extensions (Intel AMX) in the 4th Gen Intel Xeon Scalable processors yield breakthrough results.