
Earlier this week, as part of Intel’s 4th Generation Xeon Scalable processors launch (formerly Codenamed Sapphire Rapids), we announced that our technology improves low-latency BERT-Large inference throughput by over two orders of magnitude. Read our press release for more details. In this blog post I’ll walk through the details of Intel’s latest release, what makes it a great fit for our neuroscience-based technology, and how our collaboration led to dramatic performance improvements for throughput and latency.
The Rise of Transformers in NLP
In recent years large transformer models have delivered game-changing improvements in accuracy across a wide range of application spaces. Since their invention in 2017, transformers rapidly became de rigueur for natural language processing (NLP), began displacing established convolutional networks in computer vision and continue to deliver SoTA results across an ever-expanding range of applications.
These accuracy improvements come at a cost. While the first transformer models were already large, subsequent transformers have increased in size exponentially, rapidly increasing from the 100-million parameters associated with BERT-Base, to today’s GPT models with 10s or even 100s of billions of parameters. As a result, using these models is not cheap. For example, a single A100 GPU is capable of performing over 30K inference operations/second when using ResNet-50, but only 1.7K operations/second when using BERT-Large [1]. In addition to the reduced throughput, the latency of transformer-based inference operations is also, unsurprisingly, significantly higher.
As a result, there are many application spaces where the use of large transformer models is either simply cost prohibitive or is actually prevented by latency constraints. For instance, in conversational AI applications, the system must return a [hopefully intelligent] response or perform a useful action in relatively short time period following a user action. The perceived response time is the round-trip time observed by the user and includes many miscellaneous overheads in addition to the core inference operation, significantly reducing the time available to perform model inference.
Leveraging Intel’s New AMX Instructions
For peak inference performance, GPUs have traditionally been considered the gold standard, delivering world-beating throughput and latency metrics. However, other hardware manufacturers have not been idle. Intel has just released their latest 4th generation Xeon server processor, codenamed Sapphire Rapids [2].
For more than a decade, Intel’s approach to accelerating machine learning applications has been via the AVX (Advanced Vector eXtensions) instructions, including VNNI (Vector Neural Network Instructions) support for accelerating quantized models. With Sapphire Rapids, Intel introduces AMX (Advanced Matrix eXtensions) support [3]. Unlike the traditional AVX instructions that perform operations, such as a Multiply-Accumulate operations, on relatively short vectors (e.g., 512-bits), AMX operations offload entire mini matrix multiplication operations. AMX does not operate from a core’s existing register files, but introduces dedicated resources for holding operands during processing, with each processor core containing eight 1KB (arranged as 16 rows of 64-bytes) AMX “tiles”. Each tile is loaded directly from the memory hierarchy via a single AMX instruction, and, once the necessary tiles have been populated, matrix multiplication operations can be invoked on the tiles. These operations are non-blocking and other operations can be undertaken using the core while the AMX operations complete (there is sharing of certain resources between the AMX unit and the remainder of the core). AMX operates on BF16 or INT8 data types, rather than the FP32 data types that are the forte of AVX, and repeated tile loads and AMX matrix multiplication operations are required to synthesize the large matrix multiplication operations associated with deep learning models.
On Sapphire Rapids there is one AMX unit per core, for a total of up to 56 units per socket. The aggregate performance delivered by these AMX units is significantly higher than what is achievable via use of the AVX instructions.
Numenta + Intel Turn Transformers into an Ideal Real-time AI Solution
Based on our decades of neuroscience research, we have developed optimized versions of transformer models, including BERT-Base and BERT-Large. These models, while delivering equivalent accuracy, significantly outperform traditional BERT models (e.g., the versions you find on Huggingface.com). Numenta’s inference solution takes full advantage of a processor’s AVX support and, on existing x86 processors, delivers a 10X throughput improvement and a 10X latency reduction compared with standard BERT model ONNX models (and a 20X improvement compared with PyTorch-based inference).
Given our leadership in high performance inference for transformer models, and as part of our broader collaboration with Intel, Numenta was provided early access to Intel Sapphire Rapids processors. We optimized our models, and our core compute kernels to take full advantage of these AMX instructions, with some impressive results. To demonstrate these results, and ensure a fair comparison, we integrated our technology into Intel’s OpenVINO toolkit [4] and compared the inference performance observed using our models on Sapphire Rapids with performance observed on a variety of processors using traditional BERT models. In Figure 1 we illustrate the throughput improvements achieved when comparing Numenta’s BERT model on Sapphire Rapids with an equivalent Hugging Face model running on 48-core AMD Milan, a 32-core Intel 3rd Generation Xeon (Ice Lake), and a 56-core Intel Sapphire Rapids processor. This benchmark involves using OpenVINO to benchmark ONNX BERT-Large SQuAD models and optimizing for peak throughput in a server mode environment (batch size is one).

In Figure 1, inference performance is normalized with respect to the results achieved on an AMD Milan processor and illustrates that Numenta delivers more than 70X improvement over a Hugging Face model running on an AMD Milan processor and a 62X improvement compared to an Intel Ice lake processor! Other performance claims we’ve seen include Hugging Face documenting an 8x acceleration of PyTorch Transformers and TensorFlow announcing a nearly 20x speedup. Numenta’s inference solution integrates seamlessly into most MLOps deployments, providing customers with a frictionless path to adoption.
Breaking the Latency Barrier for Conversational AI
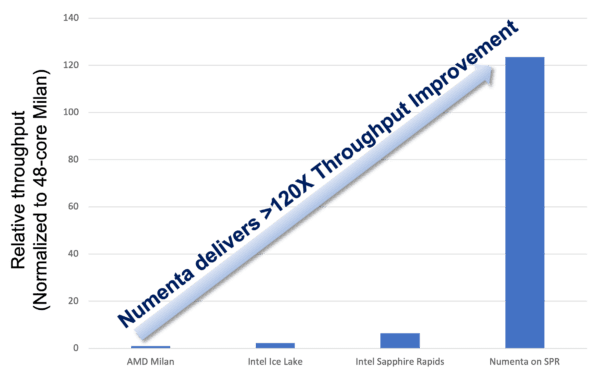
In Figure 1, delivering peak throughput is the sole objective and latency of the inference operations is of secondary importance. As discussed, for real-time applications where there are maximum latency restrictions, the objective changes: achieving peak throughput, while respecting the max latency requirement. These benchmark results are shown in Figure 2. In this example, BERT-Large SQuAD models are again benchmarked, but are now subject to the maximum response latency of 10ms that is often touted as a key latency threshold in many real-time applications.
In this environment the benefits of Numenta’s solution are even more apparent. Firstly, on other processors using the standard OpenVINO Toolkit and standard BERT models, it is not possible to achieve sub-second 10ms latencies, even when the processor is lightly loaded. Secondly, even when allowing for best effort, the large number of cores required to minimize the latency of each inference operation significantly curtails the total queries that can be processed in parallel, limiting aggregate throughput. In contrast, the efficiency of the Numenta solution using AMX enables each query to be processed in under 10ms using a modest core count, delivering significant aggregate throughput; over 120X that achieved on a 48-core AMD processor.
Traditionally, low-latency inference operations using BERT-Large have been the domain of GPUs. However, with the combination of Numenta models, optimized compute kernels and Intel’s new 4th generation Xeon server processor, real-time applications can finally use a pure CPU solution to deliver high-performance inference operations, eliminating the cost and complexity associated with GPUs.
These demonstrations with Intel are only the beginning for Numenta. If you’re interested in getting these types of performance boosts, you can get early access to our AI technology through our private beta program.
References
- https://developer.nvidia.com/deep-learning-performance-training-inference
- https://www.intc.com/news-events/press-releases/detail/1595/media-alert-intel-hosts-4th-gen-xeon-scalable-and-max
- https://www.intel.com/content/www/us/en/develop/documentation/cpp-compiler-developer-guide-and-reference/top/compiler-reference/intrinsics/intrinsics-for-amx-instructions.html
- https://docs.openvino.ai/latest/home.html