This is a joint blog post co-authored by Numenta and Intel, originally posted on Intel.com.
Summary
Natural language processing (NLP) has exploded with the evolution of transformers. But running these language models efficiently in production for either short text snippets, such as text messages or chats, with low latency requirements, or long documents with high throughput requirements, has been challenging–if not impossible–to do on a CPU.
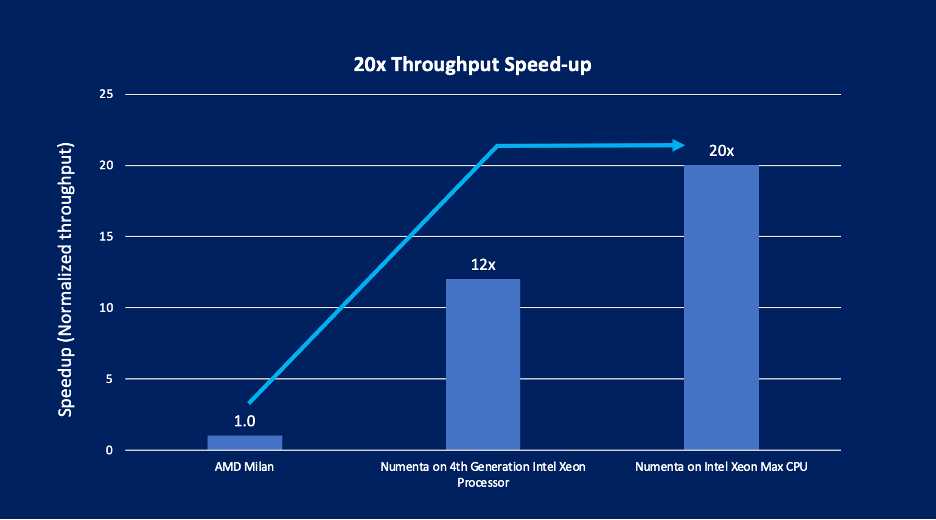
In prior work, Numenta showed how their custom-trained language models could run on 4th Gen Intel® Xeon® Scalable processors with <10ms latency and achieve 100x throughput speedup vs. current generation AMD Milan CPU implementations for BERT inference on short text sequences.1 In this project, Numenta showcases how their custom-trained large language models can run 20x faster for large documents (long sequence lengths) when they run on Intel® Xeon® CPU Max Series processors with high bandwidth memory located on the processor vs. current generation AMD Milan CPU implementations.2 In both cases, Numenta demonstrates the capacity to dramatically reduce the overall cost of running language models in production on Intel, unlocking entirely new NLP capabilities for customers.
Context
Numenta, a pioneer in applying brain-based principles to develop innovative AI solutions, has made breakthrough advances in AI and Deep Learning that enable customers to achieve 10 to more than 100X performance improvement across broad use cases, such as natural language processing and computer vision3.
Numenta has been applying their expertise in accelerating large language models, helping customers improve inference performance on both short and long sequence length tasks without sacrificing accuracy. In NLP, long sequence length tasks involve analysis of documents or similarly lengthy strings of words, as opposed to shorter sequence length tasks that may be used to analyze sentences or text fragments in conversational AI. To further accelerate and simplify the workflow for these customers, Numenta has tested Intel’s recently released Intel Xeon Max Series CPU.
The Intel Xeon CPU Max Series is an x86 CPU with high-bandwidth memory (HBM). The processor also includes the new Intel® Advanced Matrix Extensions (Intel® AMX) instructions set for fast matrix multiplication and the OpenVINO toolkit for automatic model optimization. The combination of Numenta’s neuroscience-inspired technology running on Intel Xeon Max Series CPUs led to this 20x gain in inference throughput on large language models.4 This demonstration proves that CPUs can be the most efficient, scalable, and powerful platform for inference on these large language models.
Read further to learn more about the challenge of running inference for longer sequence lengths and how the combination of Numenta technology and Intel® hardware helps to address it.
Problem
The length of text that a transformer model typically analyzes when performing each inference operation varies significantly between application spaces. For real-time conversational applications, the model might just consider a single sentence of user input, whereas for applications such as question answering or document summarization each operation might consider entire paragraphs of text (or even entire documents). Transformer models do not operate on the text data directly. Rather, the input text is tokenized and translated into a series of embedding vectors, which are fed into the model. For BERT-Large, each embedding vector comprises 1,024 elements, which, when represented using FP32, requires 4 KB of state per token.
BERT-Large can consider sequences of text that consist of up to 512 tokens, which amounts to 2 MB of state for operations on large sequence lengths. This input flows through the transformer from layer to layer, and even gets expanded when interacting with certain linear layers, e.g., in BERT-Large this can be as large as 8 MB. In addition to state associated with holding these activations, state is required to hold the model weights, and significant temporary scratch space is required as the inputs are transformed by each layer.
For newer GPT models, both the maximum sequence length and the size of the embedding vectors has increased. For instance, with GPT-J-6B, a sequence can contain up to 2,048 tokens, with each embedding representing 16 KB of state, for a total of 32 MB for operations leveraging the maximum sequence length. As a result, especially when processing large text inputs, the working set associated with an inference operation can be significant.
If we consider an inference server processing multiple input streams in parallel, while the model weights can be shared between processing operations, input state is unique to each stream, increasing linearly with the number of concurrent operations.
Another difference between application spaces is the typical batch size. For real-time applications, batch sizes are small, often just 1 (minimum latency processing, responding in real-time to user interaction). However, for offline processing, overall throughput can typically be improved (at the expense of latency), by increasing the batch size, e.g., processing 64, 128, or even 256 queries in parallel. As can be imagined, this further increases the working set required for each operation.
On today’s multi-core processors, the processor’s on-chip cache resources are shared between the cores. For instance, a 4th Gen Intel Xeon processor with 56-cores, might have a ~112 MB level-3 cache integrated on chip. While this is a significant amount of cache, the per-core resources amount to 2 MB of cache when each core is being utilized. As a result, for larger transformer models especially, even operating on larger documents, there is insufficient cache to hold all of the necessary state, requiring that data be constantly staged to and from memory. This results in significant memory bandwidth utilization.
When the working set is sufficiently small, the aggregate performance delivered by a processor can be compute bound, with the total achievable FLOPs (Floating Point Operations per second) approaching the values stated on company datasheets. However, when the working set is too large to be accommodated on chip, application performance is often first constrained by the available memory bandwidth and falls far short of the results that might be expected based solely on a processor’s compute power.
As a result, the computational power of a processor is frequently underutilized when performing inference operations with large transformer models at scale.
Solution: Dramatic Acceleration of NLP Inference with Optimized Models, CPUs
Drawing on more than two decades of neuroscience research, Numenta has defined new architectures, data structures and algorithms that deliver disruptive performance improvements. When applied to models like GPT-3 or BERT-Large, they are dramatically more efficient for inference without sacrificing accuracy. Part of this is custom-training the model with hardware-aware optimized algorithms. And part of it entails optimizing runtime to fully utilize the computing platform for inference.
Their brain-based techniques applied to a custom-trained version of BERT-Large enabled higher throughput in production. But running these models on prior generation CPU platforms like AMD Milan does not always achieve sufficient throughput to meet the needs of customers. As a result, many are forced to run with Nvidia A100s in production, which are far less cost efficient and much more time-intensive to maintain. For example, standing up a GPU system for NLP inference may take weeks of engineering time. Getting up and running with a comparable CPU platform typically takes a day or two. The same is true with any code changes required to meet the needs of changing datasets or customer demands. Each of these typically requires more engineering effort on a GPU platform versus a CPU platform.
Numenta models are more compute efficient than traditional models, but this increased efficiency tends to place higher demands on memory bandwidth. When running large deep learning models at scale, typically memory bandwidth becomes the scaling limiter. HBM triples the memory bandwidth, allowing Numenta to better leverage the computational resources.
This is where the new Xeon Max Series CPU makes a significant difference. Equipped with HBM, the aggregate off-chip bandwidth that can be sustained is over 3X higher than what’s available on processors without HBM technology.5
Finally, as discussed in more detail here, the Intel Xeon CPU Max Series processor contains other innovations that accelerate deep-learning applications, including support for Intel AMX. Intel AMX not only introduces support for 16-bit BF16 operations, reducing the memory footprint associated with activation and weights, it also delivers significantly improved peak computational performance compared with what has been traditionally possible with Intel® Advanced Vector Extensions 512 (Intel® AVX-512) instructions. Intel AMX is also designed to pair well with the Xeon Max Series CPU. Intel AMX delivers a significant compute throughput acceleration, which typically results in converting an AI inference problem from compute to bandwidth bound. The move from 32-bit to 16-bit representations with Intel AMX essentially halves the bandwidth requirements and, in the process, delivers improved inference throughput with large models. But this significant increase in potential compute throughput increases memory bandwidth demands required to fully utilize Intel AMX, thereby converting the problem to be bandwidth bound. The Xeon Max CPU, with HBM located on the processor, is designed to seamlessly handle this challenge.
Results
To demonstrate the benefits of the synergistic combination of Intel’s latest generation of processors and Numenta’s technology, we chose to demonstrate BERT-Large inference throughput improvements when using large 512-element sequence lengths. This benchmark was undertaken using optimized ONNX models, which were run using Intel’s OpenVINO toolkit and the number of concurrent streams was matched to the available processor cores. Intel’s optimized, open, and scalable software available via oneAPI, enabled Numenta to efficiently integrate their technology into OpenVINO toolkit.
The performance baseline was created using OpenVINO toolkit on a 48-core AMD Milan system, demonstrating the performance available to customers without the combination Numenta’s technology and Intel’s latest generation of Intel® Xeon® processors. As illustrated in Figure 1, moving from standard BERT-Large models (e.g., models on Huggingface.com) running on a 48-core AMD Milan system to using Numenta’s optimized BERT-Large models running on a 48-core Intel Xeon Max Series processor, inference throughput improved by over 20X.6