
Six years ago, our co-founders Jeff Hawkins and Donna Dubinsky wrote a blog titled, “What is Machine Intelligence vs. Machine Learning vs. Deep Learning vs. Artificial Intelligence (AI)?” If you visited our website at that time, you’d see our mission displayed at the top of the homepage: “Leading the new era of machine intelligence.” Machine intelligence was not a commonly used term, and artificial intelligence, machine learning and deep learning were used interchangeably rather than being clearly defined. While the definitions may have been murky, one thing was clear: none of the common approaches to creating intelligent machines demonstrated any real intelligence.
Fast forward to today and it’s no surprise that the terms have continued to evolve. Although there has been great progress in the field, the major approaches to building intelligent machines remain largely the same. In 2016 we called them Classic AI, Simple Neural Networks, and Biological Neural Networks. In this blog post, we’ll revisit these approaches, look at how they hold up today, and compare them to each other. We’ll also explore how each approach might address the same real-world problem. This analysis is intended for a general rather than technical audience, so we’ve simplified somewhat and thus beg the indulgence of technical experts who might quibble with the details.
Classic AI Approach: the rule-based system
A rule-based system is like a human being whose growth has stagnated. – Rao Desineni
The earliest approaches to AI were computer programs designed to solve problems that human brains performed easily, such as understanding text or recognizing objects in an image. Results of this work were disappointing, and progress was slow. For many problems, researchers concluded that a computer had to have access to large amounts of knowledge in order to be “smart”. Thus, they introduced “expert systems”, computer programs combined with rules provided by domain experts to solve problems, such as medical diagnoses, by asking a series of questions. If the disease was not properly diagnosed, the expert would add questions or rules to narrow the diagnosis.
Clinical Decision Support Systems, which are often used in healthcare, are an example of Classic AI. They typically contain a knowledge base comprising rules and associations of compiled data. For example, if the system was designed to determine drug interaction, a rule might state, “IF drug X and drug Y are taken, THEN alert user of side effect Z.” As new drugs are created and medical experts learn more about them, a user would need to update the knowledge base to reflect the information about the new drugs.
Classic AI has solved some clearly defined problems but is limited by its inability to learn on its own and by the need to create specific solutions to individual problems. In this regard, despite it being called artificial intelligence, it has very little in common with general human intelligence.
Artificial Neural Network Approach: Deep Learning systems
In deep learning, there’s no data like more data. – Kai Fu Lee
Some early researchers explored the idea of neuron models for artificial intelligence. When the limits of Classic AI became clear, this notion picked up steam and, with the addition of backpropagation techniques, started proving useful. The resulting technology, artificial neural networks (ANNs), was created over 60 years ago when very little was known about how real neurons worked. Since then, neuroscientists have learned a great deal about neural anatomy and physiology, but the basic design of ANNs has changed very little. Therefore, despite the name “neural networks”, the design of ANNs has little in common with real neurons. As data and processing power became more available, the emphasis of ANNs moved from biological realism to the desire to learn from data. Consequently, the main advantage of these ANNs over Classic AI was that they learned from data and didn’t require an expert to provide rules. ANN’s are part of a broader category called “machine learning,” which includes other mathematical and statistical techniques. Machine learning techniques look at large bodies of data, extract statistics, and classify the results.
ANN terminology has evolved into what’s now known as Deep Learning. Deep Learning is closer to human-like intelligence in that its layered structure allows it to learn complex patterns from data. Enabled by access to fast computers and vast amounts of data for training, Deep Learning has successfully addressed many problems such as image classification and language translation.
Although Deep Learning can solve many problems that were not solvable using Classic AI, it has several limitations. First, Deep Learning doesn’t work well when there is limited data for training; it relies on massive, labeled data sets. Second, Deep Learning requires vast amounts of computing horsepower that drive up costs and carbon footprint. A recent study from the University of Massachusetts, Amherst, showed that a single large Transformer model (a natural language processing model) consumed 656,000 kWh at a cost of $1M- $3M just to train the network.
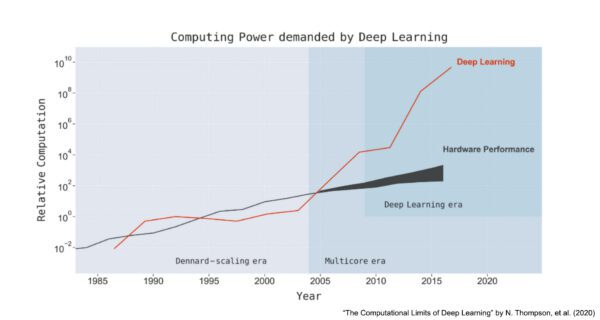
Finally, Deep Learning doesn’t handle well certain problem domains, such as:
- Where patterns are changing and thus continual learning is required. For example, a language model trained in 2019 would not know anything about COVID and would need to be entirely retrained at huge expense. In fact, it would need to be retrained frequently to keep up with current events.
- Where robustness is important. For example, we’ve all seen how a simple sticker on a stop sign can trick an image recognition system in a self-driving car.
- Where understanding is required. For example, AlphaGo’s Deep Learning model learned the game Go and defeated the world’s best players but, it couldn’t play Chess or Checkers or Tic Tac Toe, and it knew nothing about what it even means to play a game.
Essentially, Deep Learning is a sophisticated statistical technique that finds patterns in large, static data sets, but at high cost and with many constraints. While Deep Learning remains the dominant approach today, in our view, neither Deep Learning nor Classic AI is on a path to achieve true machine intelligence, or what some people refer to as AGI, Artificial General Intelligence. Rule-based systems struggle with complexity as they rely on clearly defined, static models of a particular domain. Machine learning systems create their own models, but they are also static, and they rely on large amounts of data and power. Neither can learn continuously nor can they generalize. In fact, neither system does any real live learning at all! They make models from data and once they’re deployed, they can’t be changed without reprogramming or retraining. Intelligent systems that generalize and don’t require massive amounts of labeled data will dominate, which brings us to the third approach.
Biological Neural Networks Approach: brain-derived systems
For all its success, deep neural networks are still strikingly stupid. They have no common sense. They make errors that no human baby ever would. They’re fragile and inflexible…and perhaps the most expensive one-trick pony ever invented. It’s clear that the intelligence half of AI is still lacking. – Will Douglas Heaven
Six years ago, when we wrote the original blog post, taking a brain-inspired approach to true machine intelligence was an anomaly. People were just starting to recognize the limitations of deep learning and calling for alternatives. Yet whether those alternatives needed to be inspired by, or constrained by the neuroscience, was fervently debated. That debate continues to incite strong opinions today.
Everyone agrees that the human brain is an intelligent system; in fact, it is the only system everyone agrees is intelligent. Our work at Numenta has been to study how the brain works to learn what intelligence is and what properties of the brain are essential for any intelligent system. Our goal is not to recreate the neocortex; it’s to extract the core principles that comprise an intelligent system. Since the writing of the original blog post six years ago, we have developed a framework called The Thousand Brains Theory of Intelligence, which our co-founder Jeff Hawkins describes in his book A Thousand Brains. The Thousand Brains Theory helps us understand the learning attributes necessary to create intelligent machines.
- Learning Continuously
The world is constantly changing. As a result, our model of the world needs to update constantly as well. Yet most AI systems today do not learn continuously. There is typically a separate, often extensive training process that must occur before they’re deployed. The brain, on the other hand, learns a new pattern by forming a new synapse on one dendrite branch. The new synapse doesn’t affect previously learned synapses, which is why we’re able to learn something new without forgetting. - Learning via Movement
Though we may not realize it, we learn by moving. Whether it’s a physical object like a new car, or a virtual object like a new app on your smartphone – you usually don’t learn models of these objects by studying a set of rules. You must explore them. You sit in the car and take it for a drive; you click the buttons on the app to see what each feature does. - Learning Models That Generalize
The brain is able to respond quickly and accurately to previously unseen inputs by extrapolating from knowledge it has already learned. This ability to generalize while also maintaining robustness against adversarial examples, has been a known problem in AI systems. - Learning Using Structured Representation (Reference Frames)
All knowledge in the brain is stored in reference frames. Reference frames are like maps that we use to understand how things relate to one another. We use them to make predictions, create plans, and perform movements. When we are thinking, we are moving through reference frames, retrieving information associated at each location.
Applying these biological principles to machines will enable us to create machines that are able to learn and store knowledge about the world. These machines will not be confined to performing a single task, or even a handful of tasks, exceptionally well. They will be able to learn anything.
An Example: The Roundabout
Let’s take a problem and think about how it might be addressed in the three different approaches. Again, we oversimplify a bit in order to distinguish the main differences of the three approaches.
For this example, let’s consider how a self-driving car might handle a roundabout (also called a traffic circle or rotary). How would each approach enable the car to navigate the roundabout?
The Classic AI approach would require defining and programing all the possible rules of a roundabout, i.e., rules about lanes, merging, traffic flow, and more. There are many variables such as whether there are other cars in the roundabout, whether there is a stop sign instead of a yield sign, how many lanes there are, etc. Each variable would need to be programmed in as a new rule and would have to be rationalized relative to the other rules such as which rule has priority and when.
Analogous to the Classic AI approach, the Deep Learning approach would need to be specifically customized to handle roundabouts. It would require a large set of examples of photos and videos of cars navigating through roundabouts in every possible configuration. To the extent a configuration is missed in the training – say a very different looking roundabout with 3 lanes instead of 2 – the entire model would need to be retrained.
To understand how the Biological Neural Network approach would attempt this problem, picture yourself encountering a roundabout for the first time. You might be hesitant at first and think, “What do I do?” But you have structured, reference frame-based knowledge for all the components. You have knowledge of how cars work, how lanes work, how signs work, how people drive, how accidents happen, how merging works, how traffic flows, and so on. You also have general knowledge about shapes such as circles, and how you can navigate around them. You bring together all this knowledge, generalize it, and build a new composite reference frame for roundabouts, and you do it on the fly. You might be cautious at first, but after one or two exposures, you’d have learned it. The next time you saw one, it wouldn’t matter how many other cars were there, whether there was a stop sign or a yield sign, whether it was rainy, foggy or a sunny day. You would successfully navigate the roundabout.
In summary, below are the characteristics of the three different approaches:
| Classic AI | Deep Learning | Biological Neural Network | |
|---|---|---|---|
| Associated terms | Expert systems Rule-based systems |
Artificial Neural Nets (ANNs) Machine learning |
Machine Intelligence Artificial General Intelligence (AGI) |
| Training | Programmed by experts | Trained with large, carefully curated datasets | Learned via movement with unlabeled data |
| Learns rapidly with little data | No | No | Yes |
| Learns continuously | No | No | Yes |
| Learns with structure | Yes – rules | No | Yes – reference frames |
| Learns models that generalize | No | No | Yes |
Summary
In our comparison of these three different approaches, there’s no question that Classic AI and Deep Learning have solved important problems. In fact, you can envision scenarios today where each approach would be optimal. Nonetheless, Classic AI and Deep Learning still are constrained by limitations that cannot be overcome by throwing more rules or more data at the problem. They are not on a path to true machine intelligence, and we need a new approach to get us there. Classic AI is rules-based. It has defined structure but does not learn; it’s programmed. Deep Learning is trained using data but lacks structure. Neither can adapt on the fly nor do they generalize or truly understand. To create machines that understand and generalize, we take inspiration from the brain. The Thousand Brains Theory of Intelligence offers the path to machine intelligence. If we want to build truly intelligent machines that can learn and build models of the world, The Thousand Brains Theory offers a roadmap to get us there.