Can you introduce yourself and your area of expertise?
My full name is Ali Kaan Sungur and I work as a research assistant in Middle East Technical University, Graduate School of Informatics. I’m a computer science graduate specialized in game development and real-time 3D graphics. Recently, HTM and related neuroscience became my main area of interest. I have an Ms. degree in Game Technologies and just started my PhD. in Cognitive Science. Oh, and I love cycling.
How long have you been a member of the HTM Community?
I was around during the time when HTM was discussed through mailing lists. So, I think I have been a member since 2014. There is a mail in those lists where I ask about the feasibility of an HTM agent for a video game. Fast forward 3 years and I presented HTM as a promising foundation for a game agent in my thesis.
How did you first learn of HTM?
I was prototyping a PC game called The Wonderer in 2013 where I wanted computer controlled characters which can learn and generalize the actions demonstrated by the player. After exploring a couple of traditional approaches like behavior trees, simple Bayesian behavior models, S.T.R.I.P.S., I ended up watching a Ted talk by Jeff Hawkins. The approach of HTM instantly hooked me, so I started implementing my own version for the said prototype. It took around 6 months of tinkering on HTM and deciphering NuPIC codebase to get the first version working embedded inside the engine.
Can you describe your thesis, at a high level?
As a firm believer in the power of video games as a communication tool, my main goal was to explore the feasibility of an HTM based game agent which can explore its environment and learn behaviors that are rewarding. The literature is almost non-existent on an unsupervised HTM based autonomous agent. I proposed a real-time agent architecture involving a hierarchy of HTM layers that can learn action sequences with respect to the stimulated reward. This agent navigates a procedurally generated 3D environment and models the patterns streaming onto its visual sensor shown in Figures 1 and 2.



The problem I focused on in the thesis involves a simple video game task where the agent is expected to navigate to a portal from its starting position as in Figure 3 using only the visual information.
Why did you decide to use HTM in your thesis? Did you consider other models, either from traditional machine learning or computational neuroscience?
It was more like HTM became the center of my work in time because I was intrigued with what I was learning about biological intelligence mechanisms. No other learning approach promised a biologically plausible computational model for an agent. NEF (Neural Engineering Framework) is the closest contender preferred by the cognitive science crowd. Relations between large scale neuron groups are defined via math functions and the underlying learning rule is pure math. So it is bioplausible at a larger scale. It is also not focused on relevant neurobiological research in cortical learning level as much as HTM.
Computational neuroscience models are mostly focused on isolated components rather than a universal learning algorithm or a scheme for an autonomous agent. Computational models of basal ganglia come closer in this regard and the architecture of the thesis is guided by these models as a result.
HTM is very intuitive when it comes to function and visualization. It is a model that can predict its own state, not a value that you want to optimize. You can look at the model and can decipher what is going on or if something is wrong. This is a very important attribute if you wanted to present it. I am not sure you can decipher and communicate traditional machine learning models such as LSTM or Deep Learning through visualization, this easily. They have a stronger focus on math, which serves them well in real machine learning scenarios, but I wanted something else.

Figure 4 shows what I refer to as Core, my main visualization, which keeps getting more powerful as my demands evolve. For those interested in how I built the visualizations, I’ve included more details at the end of the post.
I wanted biological relevancy, functional intuition and model transparency. At the same time, the learning it provides needed to be continuous, real-time and unsupervised for the agent I envisioned. HTM was a stronger fit for what I wanted in general.
Here is the real reason; I did not want to work years on a model which does not naturally map to my understanding of biological intelligence when there is an approach that offers me just that.
What were the results?
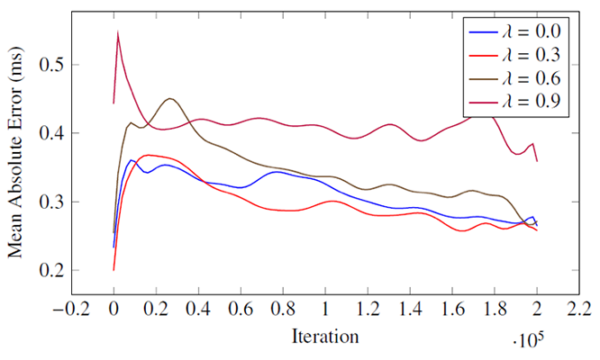
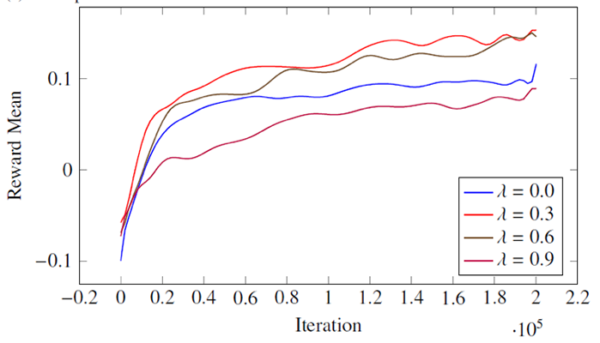
The results suggest that the agent becomes better at evaluating and predicting its state with respect to long-term reward. Moreover, the agent becomes more efficient at navigating to the portal and accomplishes the task more frequently as the time passes. I’ve included some graphs at the end of the blog post that show more details, but all in all, the results suggested that this is a promising architecture that could be utilized in a video game designed around it.
What’s next for this work?
Currently I am exploring the application of the proposed method onto a game prototype utilizing the engine. I am experimenting with a system where the player sets increasingly complex sequences for the agent to learn which is referred to as shaping in psychology. The agent then starts with the simplest one and advances to more complex ones as it passes an efficiency threshold. At the same time, I am looking on strategies to incorporate ideas from the recent sensorimotor research by Numenta. In order to expand what the agent can accomplish, I am also testing different visual sensor types (presented in the latest video on my channel) such as event based sensors and more granular movement types that work well with them.
Do you have plans to use HTM in the future?
The thesis is an output of the work in its current form but the proposed HTM network is constantly being modified and it is iteratively getting better. This is a long endeavor and hopefully the game will communicate what I envision via its HTM agents. In the very least, we will have a much better understanding of brain mechanisms through HTM theory and that alone is an exciting promise for me.
Where can people follow this work?
For those who wish to read my thesis, you can download it here. Whenever I produce something worthwhile, it is usually uploaded to my YouTube channel as a video. There is a supplementary visual demo for the thesis there. I am also an active Numenta forum user where readers can reach me and join in the discussion of this topic on the forum. Readers can also contact me at ksungur@metu.edu.tr.
Technical details on the real-time agent architecture with a hierarchy of HTM layers
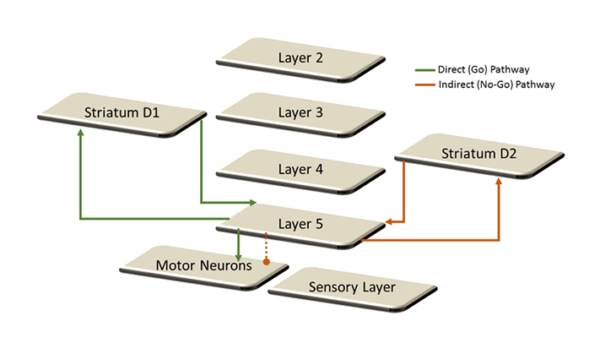
HTM research is driven by neurobiological evidence. Similarly, the proposed architecture imitates the interplay of basal ganglia, layer 5 and motor areas. Figure 5 highlights the two competing reward pathways (referred as direct and indirect pathways) which result in the actions of the agent. The mechanism is abstracted from the computational models of basal ganglia and the relevant neurobiological research is provided.
The agent can also be guided in a straightforward way so that it learns specific wanted sequences. During guidance, everything that the player sees and does are fed to the agent as if the agent is living the experience of the player. The proposed method runs real time, learns continuously and optimizes its behaviors with respect to the long-term rewards. You can start learning unsupervised, teach something to the agent, store it and continue at a later session. So, it is a practical NPC architecture. NPC (non-player character) includes all the computer controlled actors in a video game other than the player. The baddies that we shoot, the pets that follow us, citizens of our city etc. are all NPCs of a video game.
It’s not an easy task to create HTM visualizations, and yours were particularly impressive. How did you go about creating them?
Interestingly the visualizations were born out of necessity. Trying to debug thousands of neurons through development environment was very time consuming. I had an engine at hand, so first I just rendered active minicolumns and the synapses activating them in a rectangular grid to see that the layers run as expected. Figure 6 shows the first visualization two years ago.

Then came neuron and column selection mechanisms with their own property windows as I needed to see them. These were followed by playback options, coloring schemes, connectome statistics, and serialization capabilities along with a variety of synaptic visualizations as I wanted to visually access increasingly complex information while the architecture is running. Under the hood, the user interface runs on DirectX 11 API and it consists of some basic abilities: rendering a 2D texture, drawing lines, printing words, and some transparency.
More details on the results
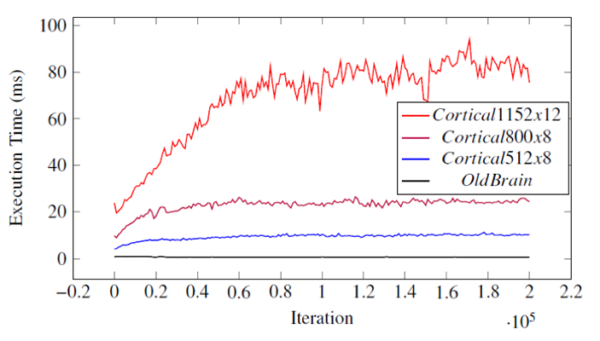
The agent becomes better at evaluating and predicting its state with respect to the long-term reward measured by Mean Absolute Error in the first graph below. The agent also becomes more efficient at navigating to the portal and accomplishes the task more frequently as the time passes. This is measured by the moving average reward in the second graph. The third graph below shows that the layer network can run in real time for layer sizes smaller than 800 columns and 8 neurons per column. You can store and retrieve this agent which has 10 million synapses in around 3 seconds which takes up 50MB of storage space.