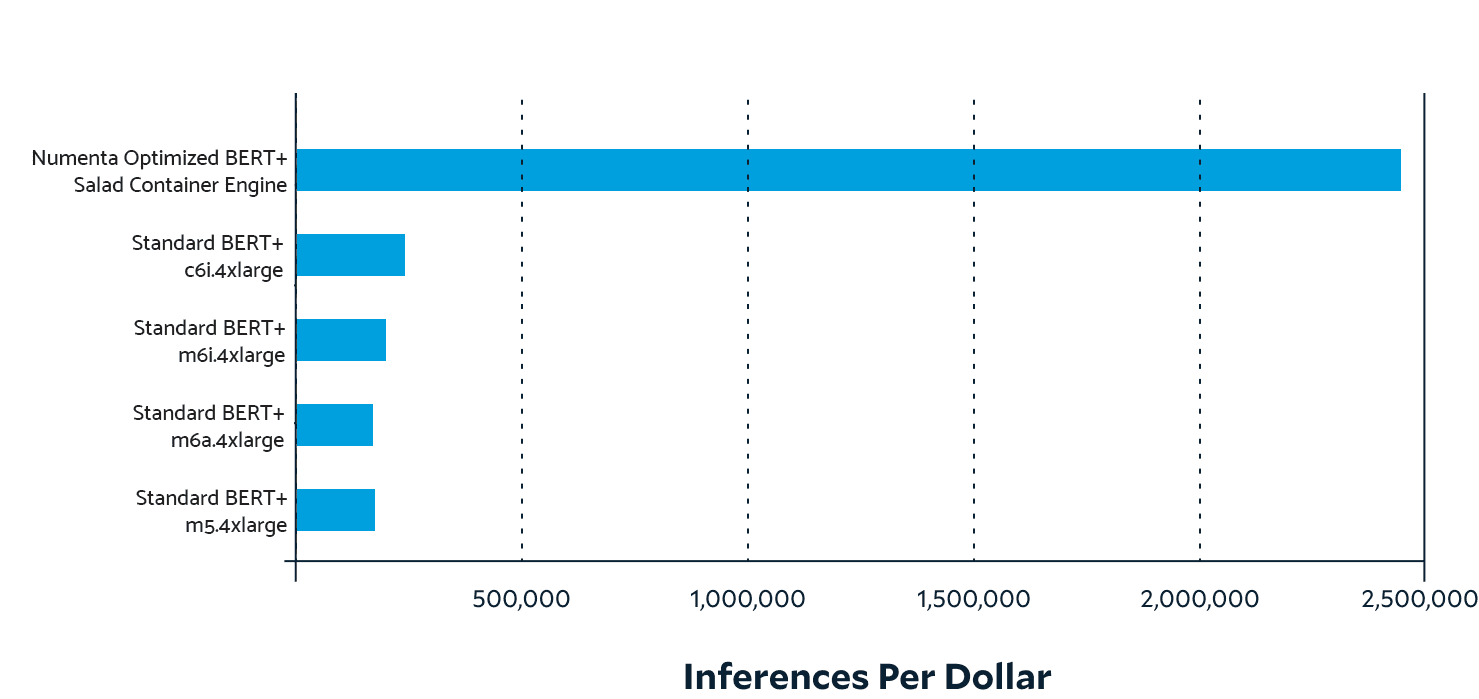

Developing AI-powered games on existing CPU infrastructures without breaking the bank
AI is opening a new frontier for gaming, enabling more immersive and interactive experiences than ever before. NuPIC enables game studios and developers to leverage these AI technologies on existing CPU infrastructure as they embark on building new AI-powered games.

