
NOTE: This blog was originally published in May 2022. We have since updated and republished the content to reflect the latest developments in the AI landscape. You can find the updated 2023 version here.
Over the last ten years, AI, specifically deep learning, has yielded remarkable results. When Siri understands what you say, when Facebook identifies your cousin, when Google Maps reroutes you, chances are that a deep learning system is involved.
What is less noticed is that these models are churning away at a staggering cost, not just in terms of dollars and cents, but also in terms of energy consumed. On its current trajectory, AI will only accelerate the climate crisis. In contrast, our brains are incredibly efficient, consuming less than 40 watts of power. If we can apply neuroscience-based techniques to AI, there is enormous potential to dramatically decrease the amount of energy used for computation and thus cut down on greenhouse gas emissions. This blog post aims to explain what causes this outsized energy consumption, and how brain-based techniques can address AI’s incredibly high energy cost.
Why does AI consume so much energy?
First, it is worth understanding how a deep learning model works in simple terms. Deep learning models are not intelligent the way your brain is intelligent. They don’t learn information in a structured way. Unlike you, they don’t understand cause-and-effect, context, or analogies. Deep learning models are “brute force” statistical techniques. For example, if you want to train a deep learning model to identify a photo of a cat, you show it thousands of images of cats that have been labeled by humans. The model does not understand that a cat is more likely than a dog to climb up a tree or play with a feather, so unless it is trained with images of cats that include trees and feathers, it is unaware that the presence of these objects would aid in identifying a cat. To make these inferences, it needs to be trained in a brute force way with all possible combinations.
The enormous energy requirement of these brute force statistical models is due to the following attributes:
- Requires millions or billions of training examples. In the cat example, pictures are needed from the front, back, and side. Pictures are needed of different breeds. Pictures are needed with different colors and shadings, and in different poses. There are an infinite number of possible cats. To succeed at identifying a novel cat, the model must be trained on many versions of cats.
- Requires many training cycles. The process of training the model involves learning from errors. If the model has incorrectly labeled a cat as a raccoon, the model readjusts its parameters and classifies the image as a raccoon, then retrains. It learns slowly from its mistakes, which requires more and more training passes.
- Requires retraining when presented with new information. If the model is now required to identify cartoon cats, which it has never seen before, it will need to be retrained from the start. It will need to have blue cartoon cats and red cartoon cats added to the training set and be retrained from scratch. The model cannot learn incrementally.
- Requires many weights and lots of multiplication. A typical neural network has many connections, or weights, that are represented by matrices. For the network to compute an output, it needs to perform numerous matrix multiplications through subsequent layers until a pattern emerges on top. In fact, it often takes millions of steps to compute the output of a single layer! A typical network might contain dozens to hundreds of layers, making the computations incredibly energy intensive.
How much energy does AI consume?
A paper from the University of Massachusetts Amherst stated that “training a single AI model can emit as much carbon as five cars in their lifetimes.” Yet, this analysis pertained to only one training run. When the model is improved by training repeatedly, the energy use will be vastly greater. Many large companies, which can train thousands upon thousands of models daily, are taking the issue seriously. This recent paper by Meta is a good example of one such company that is exploring AI’s environmental impact, studying ways to address it, and issuing calls to action.
The latest language models include billions and even trillions of weights. One popular model, GPT-3, has 175 billion machine learning parameters. It was trained on NVIDIA V100, but researchers have calculated that using A100s would have taken 1,024 GPUs, 34 days and $4.6million to train the model. While energy usage has not been disclosed, it’s estimated that GPT-3 consumed 936 MWh. Google AI just announced the Pathways Language Model with 540 billion parameters. As the models get bigger and bigger to handle more complex tasks, the demand for servers to process the models grows exponentially.
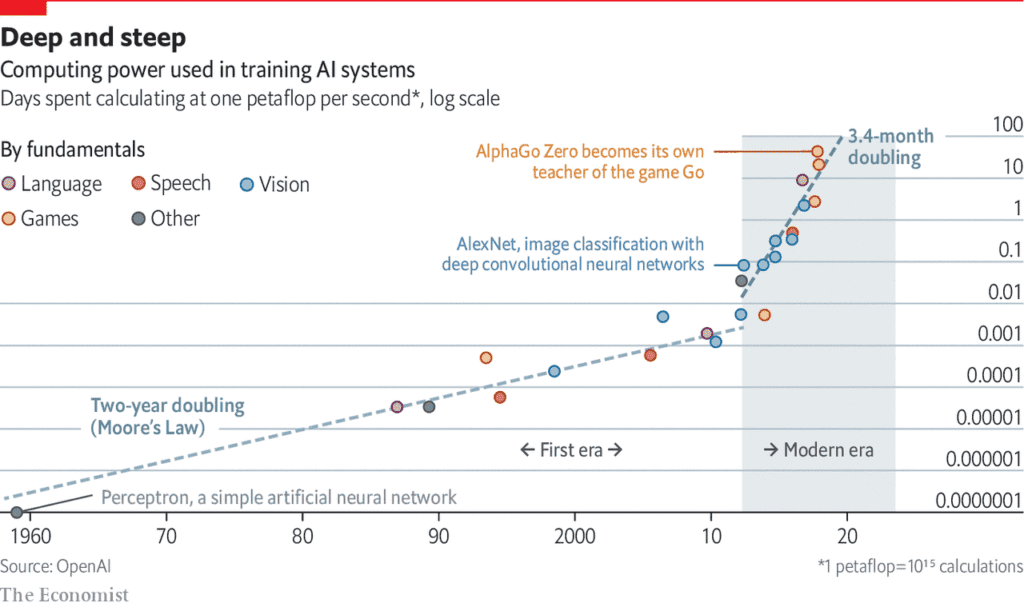
Computer power used in training AI systems has exponentially increased in the era of deep learning. (source)
Since 2012, the computational resources needed to train these AI systems have been doubling every 3.4 months. One business partner told us that their deep learning models could power a city. This escalation in energy use runs counter to the stated goals of many organizations to achieve carbon neutrality in the coming decade.
How can we reduce AI’s carbon footprint?
We propose to address this challenging issue by taking lessons from the brain. The human brain is the best example we have of a truly intelligent system, yet it operates on very little energy, essentially the same energy required to operate a light bulb. This efficiency is remarkable when compared to the inefficiencies of deep learning systems.
How does the brain operate so efficiently? Our research, deeply grounded in neuroscience, suggests a roadmap to make AI more efficient. Here are several reasons behind the brain’s remarkable capability to process data without using much power.
1/ Sparsity
Information in the brain is encoded as sparse representations, i.e., a long string of mainly zeros with a few non-zero values. This approach is different than typical representations in computers, which are normally dense. Because sparse representations have many zero elements, these can be eliminated when multiplying with other numbers, with only the non-zero values being used. In the brain, representations are extremely sparse: as many as 98% of the numbers are zero. If we can represent information in artificial systems with similar levels of sparsity, we can eliminate a huge number of computations. We have demonstrated that using sparse representations in inference tasks in deep learning, such as recognizing a cat in a vision system, can improve power performance from 3 to over 100 times, depending on the network, the hardware platform, and the data type, without any loss of accuracy.
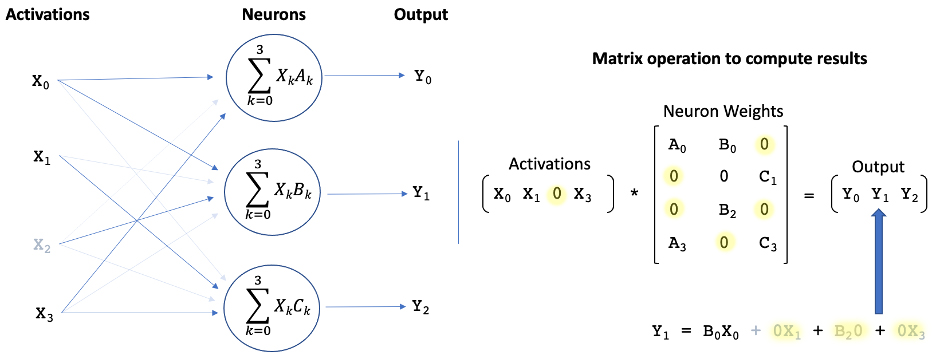
A Closer Look: Applying sparsity to machine learningThere are two key aspects of brain sparsity that can be translated to DNNs: activation sparsity and weight sparsity. Sparse networks can constrain the activity (activation sparsity) and connectivity (weight sparsity) of their neurons, which can significantly reduce the size and computational complexity of the model.
When both weights and activations are sparse in a neural network, it is only necessary to compute a product if it contains a non-zero element, hence a large fraction of products can be eliminated (adapted from source). |
2/ Structured data
Your brain builds models of the world through sensory information streams and movement. These models have a 3-D structure, such that your brain understands that the view of the cat’s left side and the view of the cat’s right side do not need to be learned independently. The models are based on something we call “reference frames.” Reference frames enable structured learning. They allow us to build models that include the relationships between various objects. We can incorporate the notion that cats may have a relationship to trees or feathers without having to see millions of instances of cats with trees. Building a model with reference frames requires substantially fewer samples than deep learning models. With just a few views of a cat, the model should be able to transpose the data to understand alternate views of the cat, without being trained specifically on those views. This approach will reduce the size of training sets by several orders of magnitude.
A Closer Look: Structured learning with reference framesReference frames are like gridlines on a map, or x,y,z coordinates. Every fact you know is paired with a location in a reference frame, and your brain is constantly moving through reference frames to recall facts that are stored in different locations. This allows you to move, rotate and change things in your head. You can imagine what a blue cartoon cat looks like instantly based on your reference frame of what a cat looks like in real life and the color blue. You don’t need to look at 100 pictures of blue cartoon cats from all angles to imagine it.
Reference frames represent where your body is relative to its environment, and where things are relative to each other. (source) |
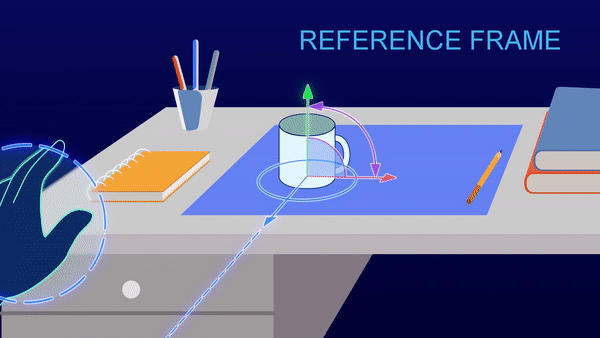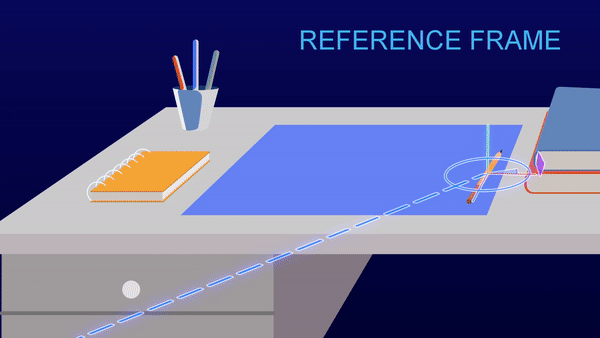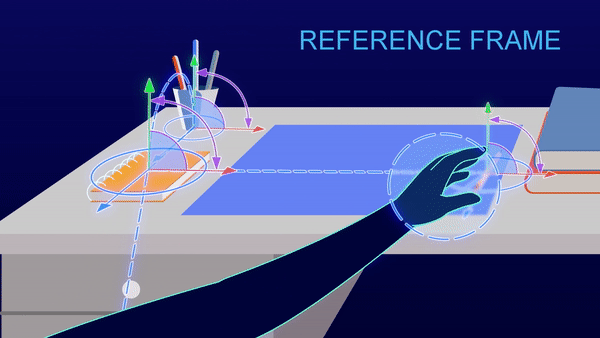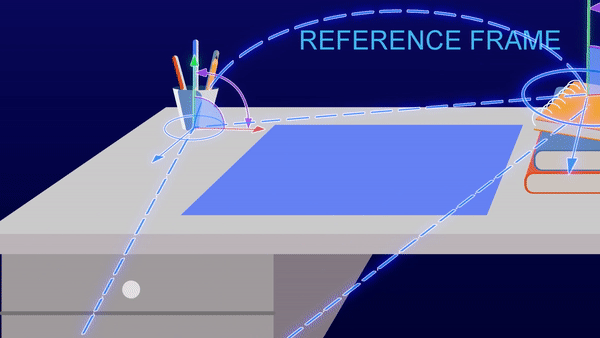
3/ Continual learning
Your brain learns new things without forgetting what it knew before. When you see an animal for the first time, say a coyote, your brain does not need to relearn everything it knows about mammals. It adds a reference frame for the coyote to its memory, noting similarities and differences from other reference frames, such as a dog, and sharing common sub-structures, such as tails and ears. This small incremental training requires very little power.
A Closer Look: Multi-task and continual learning with active dendritesA biological neuron has two kinds of dendrites: distal and proximal. Only proximal dendrites are modeled in the artificial neurons we see today. We have demonstrated that by incorporating distal dendrites into the neuron model, the network is able to learn new information without wiping out previously learned knowledge, thereby avoiding the need to be retrained.
Comparison between a point neuron used in typical deep learning networks, a biological pyramidal neuron seen in the neocortex, and an active dendrites neuron that incorporates principles from the pyramidal neuron. (adapted from source) |
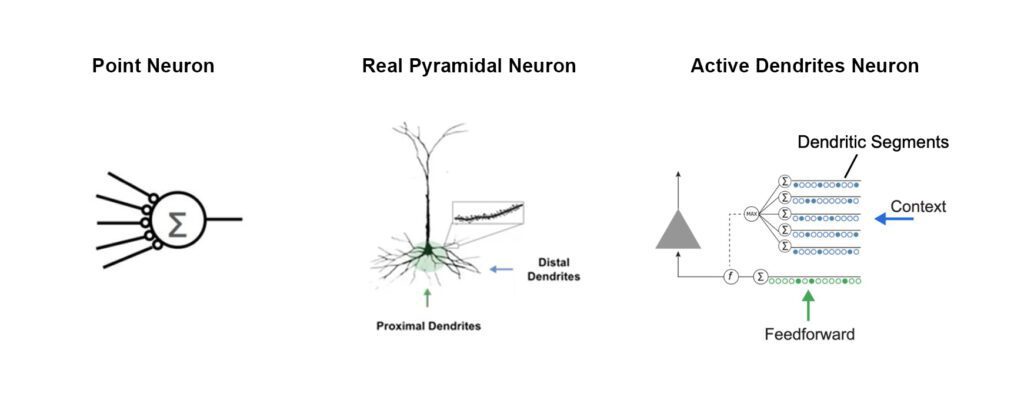
4/ Optimized hardware
Today’s semiconductor architecture is optimized for deep learning, where networks are dense and learning is unstructured. But if we want to create more sustainable AI, we need hardware that can incorporate all three of the above attributes: sparsity, reference frames, and continual learning. We have already created a few techniques for sparsity. These techniques map sparse representations into a dense computing environment and improve both inference and training performance. Over the long run, we can imagine architectures optimized for these brain-based principles that will have the potential to provide even more performance improvements.
A Closer Look: Complementary SparsityIn 2021 we introduced Complementary Sparsity, a technique that enables high performance by leveraging both sparse weights and sparse activations, resulting in more resource-efficient implementations in hardware. We recently demonstrated 100X improvement in throughput and energy efficiency running inference tasks on FPGAs using Complementary Sparsity.
80% Complementary Sparsity packs 5 sparse matrices (with sparse weights) into a single “dense” matrix and combines that with sparse activations for processing. (adapted from source) |
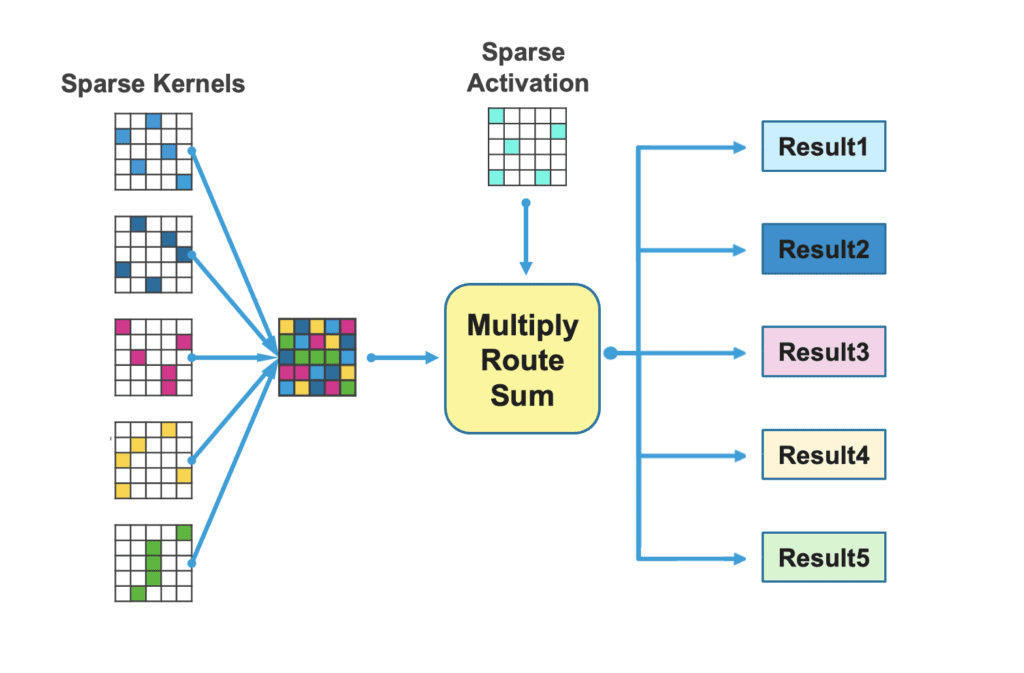
Towards a more sustainable future
Continuing to build larger and more computationally intensive deep learning networks is not a sustainable path to building intelligent machines. At Numenta, we believe a brain-based approach is needed to build efficient and sustainable AI. We have to develop AI that works smarter, not harder.
The combination of fewer computes, fewer training samples, fewer training passes, and optimized hardware multiplies out to tremendous improvements in energy usage. If we had 10x fewer compute, 10x fewer training samples, 10x fewer training passes and 10x more efficient hardware, that would lead to a system that was 10,000x more efficient overall.
In the short term, we are focusing on reducing energy consumption in inference substantially. In the medium term, we are applying these techniques to training, and we expect even greater energy savings as we reduce the number of training passes needed. Over the long term, with enhanced hardware, we see the potential for thousandfold improvements.
Abstracting from the brain and applying the brain’s principles to current deep learning architectures can propel us towards a new paradigm in AI that is sustainable. If you’d like to learn more about our work on creating energy-efficient AI, check out our blogs below.