Abstract:
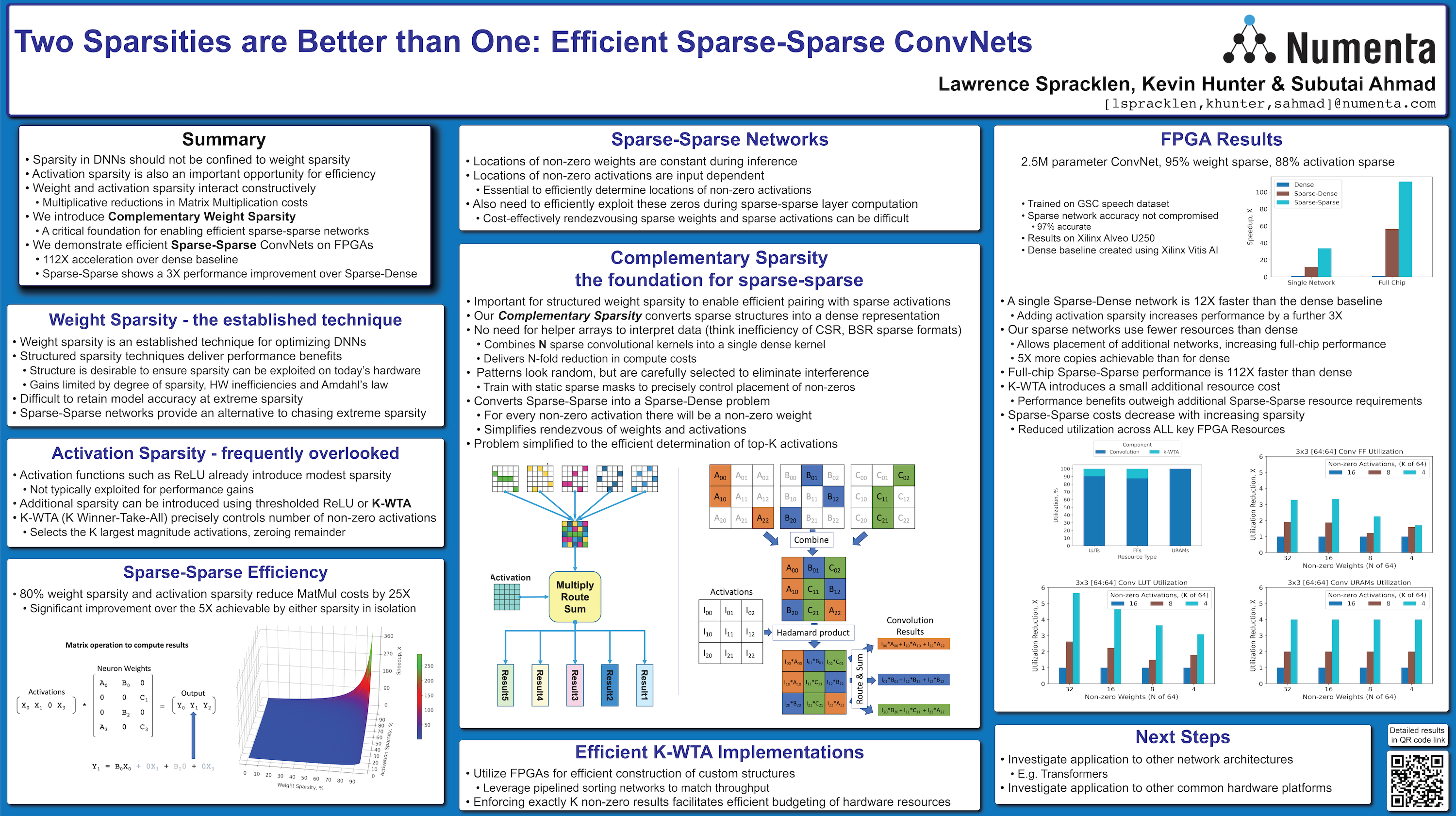
As research into creating sparse DNNs has exploded in popularity, attention has remained largely focussed on weight sparsity. However, there is a second dimension to sparsity, Activation Sparsity. Activation Sparsity limits the number of non-zero outputs from each layer, and interacts synergistically with weight sparsity, creating the potential for multiplicative reductions in compute costs. However, due to the dynamic nature of activations, exploiting Activation Sparsity has proven more challenging than weight sparsity.
In this poster, we present Complementary Sparsity, a structured weight sparsity technique that provides a foundation for the efficient exploitation of Activation Sparsity and Sparse-Sparse DNNs. We demonstrate the effectiveness of this technique using ConvNets on FPGAs. Using Complementary Sparsity combined with K-Winner Take All (K-WTA) techniques to control the number of non-zero activations, we demonstrate a 112X increase in performance over an optimized dense baseline.
You can find additional resources on this topic here: