Today’s machine learning techniques have accomplished a great deal but are widely acknowledged to be running into fundamental limitations, including their need for enormous compute power. Unlike deep learning networks used in machine learning, the brain is highly efficient, consuming less power than a lightbulb. How is the brain so efficient? There are many reasons, but at its foundation is the concept of sparsity. At any given time, no matter where you look in the brain, only a small percentage of neurons in the brain are active, as the brain stores and processes information as sparse representations. In addition, unlike deep learning networks, the connectivity between neurons in the brain is also highly sparse.
Sparsity offers new approaches for machine learning researchers to address performance bottlenecks as they scale to more complex tasks and bigger models. However, fully exploiting sparse networks can be difficult with today’s hardware limitations. As a result, most systems perform best with dense computations, and most sparse approaches today are restricted to narrow applications. Numenta’s sparse networks rely on key aspects of brain sparsity, most notably: activation sparsity (number of active neurons) and weight sparsity (interconnectedness of neurons). The combination of the two yields multiplicative effects, enabling large efficiency improvements.
About
This paper demonstrates the application of Numenta’s brain-inspired, sparse algorithms to machine learning. We used these algorithms on Xilinx™ FPGAs (Field Programmable Gate Array) and the Google Speech Commands (GSC) dataset to show the benefits of leveraging sparsity in order to scale deep learning models. In November 2020, we announced a 50x performance speed up in deep learning networks. In May 2021, our results show that sparse networks are 100 times faster than non-sparse networks on an inference task with competitive accuracy.
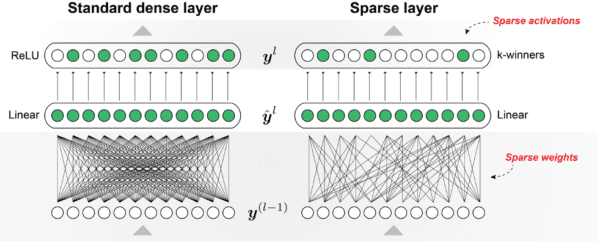
Standard dense layer vs. our sparse layer. Our sparse layer contains both sparse weights and sparse activations.
Frequently asked questions
Q. What was the purpose of this paper?
This paper demonstrates how sparsity can achieve significant acceleration and power efficiencies while maintaining competitive accuracy in deep learning networks. It also aims to break through the performance bottleneck in today’s machine learning techniques in order to achieve scaling improvements that enable significant energy savings and reduce power consumption.
Q. What is the key takeaway?
Our sparse-sparse implementation can process data 100 times faster than the dense implementation on the platform. The overall system speedup is due in part to the multiplicative effects yielded by taking full advantage of both sparse weights and sparse activations.
Q. How were the performance tests conducted?
We chose the Google Speech Commands (GSC) dataset, which consists of 65,000 one-second long utterances of keywords spoken by thousands of individuals. The task is to recognize the word being spoken from the audio signal. We used an FPGA (Field Programmable Gate Array) as the hardware platform to run the performance tests because of the flexibility it provides in handling sparse data efficiency. We do expect that current generation CPUs and GPUs can achieve benefits from sparsity as well, though not as dramatic as in FPGAs. In the future, we propose exciting architecture enhancements to CPUs and GPUs that would enable greater use of sparsity for substantial performance gains.
Q. What are the implications?
This dramatic speed improvement could provide great benefits, enabling:
- Implementation of far larger networks using the same resource
- Implementation of more copies of networks on the same resource
- Implementation of more sophisticated sparse networks on edge platforms with limited resources where dense networks do not fit
- Massive energy savings and lower costs due to scaling efficiencies
This technology demonstration is the beginning of a much broader roadmap that we have laid out, based on our deep neuroscience research. Beyond sparsity, as we add more elements of our neocortical model, we expect additional benefits in unsupervised learning, robustness and sensorimotor behavior.
Q. Where can I find out more?
We have several additional resources for people who want to learn more:
- Technology Demonstration Visualizations
- How Can We Be So Dense? The Benefits of Using Highly Sparse Representations
- Sparse Distributed Representations – (BAMI Chapter 3)
- Sparse Distributed Representations: Our Brain’s Data Structure
- HTM Forum – a great resource for further questions and discussion on the paper. The authors are active participants in the forum.