Meeting industry latency requirements while reducing costs
Conversational AI, which refers to technologies that allow consumers to engage in human-like interactions with computers, is projected to be a $40 billion industry by 2030. As it continues to grow, so does the demand for real-time AI. While large language models like transformers have become fundamental for many Natural Language Processing applications, their complexity and size create considerable latency bottlenecks. As a result, it is challenging and costly for companies to deploy these models for real-time applications.
SOLUTION
Numenta Optimized Inference
With unique acceleration techniques built on neuroscience insights, our optimizations deliver high inference throughput at ultra low latencies on off-the-shelf CPUs. Our solutions enable customers to easily integrate and deploy our technology on conventional hardware.
RESULTS
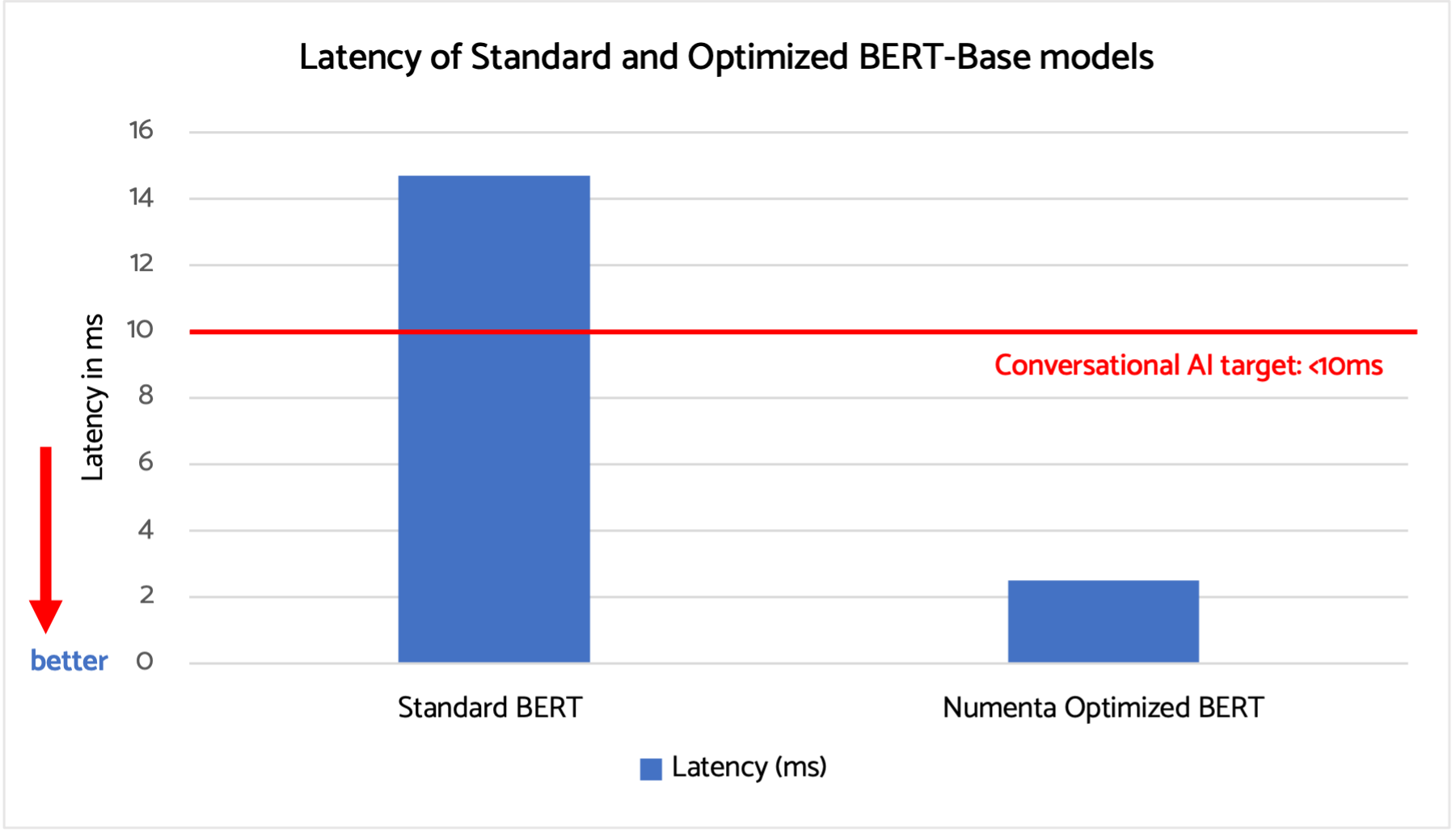
Achieving <3ms latency on CPUs
Time-sensitive applications, like virtual assistants and online chats, require ultra-low latencies, typically under 10ms. When we optimize for latency, our BERT-Base model is well within the target, achieving 2.5ms latency. This is more than 5X faster than the standard BERT-Base model running on Microsoft’s hand-optimized ONNX runner.
Models are running BERT-Base on an Intel Xeon server (AWS m6i.4xlarge), with Sequence Length 64, Batch Size 1, using 1 Socket and 4 Cores
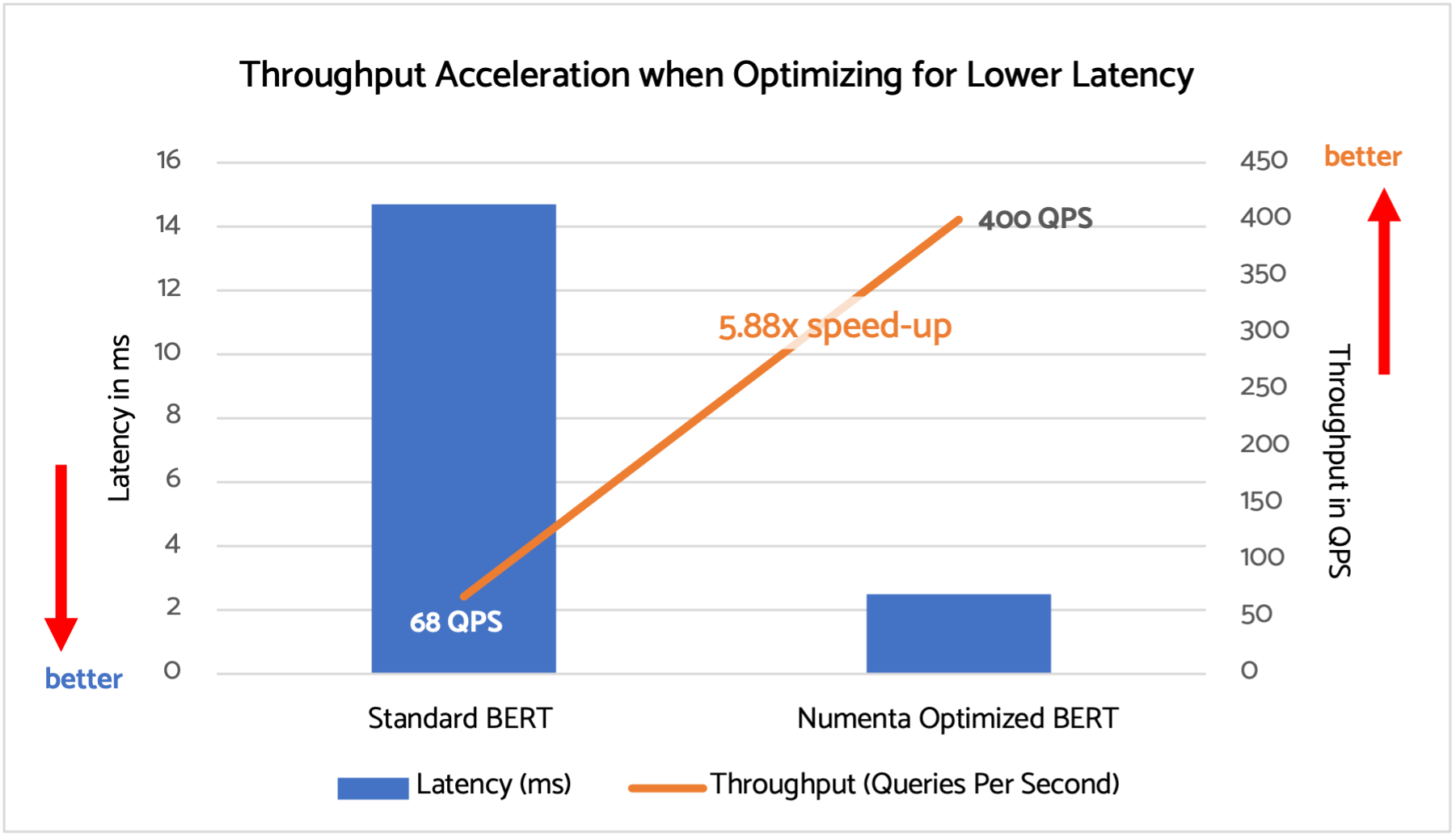
In this example, although we are optimizing for latency we still get a 5.88x throughput speed-up as shown in the chart below.
Models are running BERT-Base on m6i.4xlarge, with Sequence Length 64, Batch Size 1, 1 Socket and 4 Cores
BENEFITS
Turning Transformers into an attractive real-time AI solution
Our sub-3ms latency results open new possibilities for companies with time-sensitive AI applications, who can finally deploy Transformer models in production:
Reduces cost and complexity of Transformers
Makes Transformers a high-performance, cost-effective solution
With our neuroscience-based optimization techniques, we shift the model accuracy scaling laws such that at a fixed cost, or a given performance level, our models achieve higher accuracies than their standard counterparts.
Numenta technologies combined with the new Advanced Matrix Extensions (Intel AMX) in the 4th Gen Intel Xeon Scalable processors yield breakthrough results.